Updates: The text below the video was added later on 4/17, and the graphic was added 4/18.
For me the evidence highlight of TEDMED last week was a talk by Ben Goldacre MD (@BenGoldacre), a charming and articulate doctor who’s dug deeply into what seems to be scurrilous business: suppression of evidence that doesn’t favor the drug being studied. So he’s undertaken a project to dig up all the clinical trials that were registered with the FDA, and find the ones that never got published.
Think this is nit-picking? Watch this 6 minute hallway chat I had with him, late the last night of the conference. He calls it “The cancer at the core of evidence-based medicine.”
The video is hand-held-iPad shaky – forgive me, ignore it, just listen to the audio.
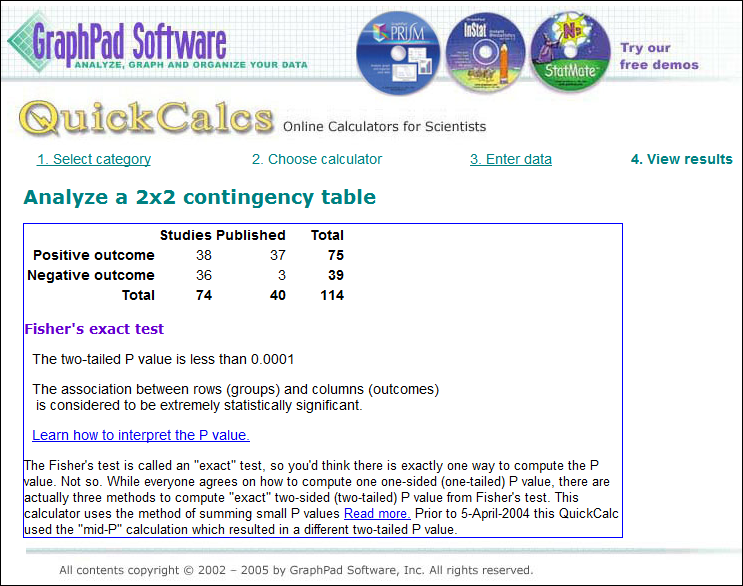
Example: in a survey of all 74 trials ever submitted to the FDA for anti-depressants, about half had positive outcomes – but only 40 papers were published, of which 37 were positive. Of the 36 negative outcomes, only 3 were published.
So here’s how that boils down: (Graphic added 4/18)
 Reality: 51% positive
Reality: 51% positive
Published: 92% positive (37/40)
Withheld / unpublished: 97% negative (33/34)
[Added 4/18] At right is a calculation from GraphPad.com of the probability that this is random: p < .0001 (1 in 10,000), “extremely statistically significant.” (See discussion of realist “Fat Tony” in this comment.)
That much skewing is an extreme example, but Goldacre says only about half the trials that are conducted are ever published, and (p=.0392) positive outcomes are twice as likely to be published as unfavorable ones. [End 4/18 addition]
Impact:
- Inhibits patients from getting good information
- Inhibits doctors from having good information, too, with which to treat their patients
- Makes an absolutely mockery of evidence-based medicine
- As Goldacre points out, it’s a severe disservice to the patients who put themselves at risk by being in a clinical trial to help improve the body of scientific knowledge.
I’d welcome thoughts from all, especially clinicians, on how to spread awareness of this. Goldacre says he’s going to start AllTrials.org and will plumb the database of all trials ever registered, to find and publish their outcomes.
There’s more in his TEDMED talk than in this 6 minute video but for now this is a start.
———-
Related posts on this blog:
ORLANDO, Feb. 27 — Newly unsealed court documents suggest that AstraZeneca tried to minimize the risk of diabetes and weight gain associated with its antipsychotic drug quetiapine (Seroquel), in part by “cherry-picking” data for publication. … lawsuits by some 9,000 people who claim to have developed diabetes while taking the drug. … a 1999 e-mail indicating that the company had “buried” three clinical trials and was considering doing so with a fourth. … Another … discussed ways to “minimize” and “put a positive spin” on safety data from a “cursed” study— one of those later described as “buried.”
A recurring theme on this blog is the need for empowered, engaged patients to understand what they read about science. It’s true when researching treatments for one’s condition, it’s true when considering government policy proposals, it’s true when reading advice based on statistics. If you take any journal article at face value, you may get severely misled; you need to think critically.
Sometimes there’s corruption (e.g. the fraudulent vaccine/autism data reported this month, or “Dr. Reuben regrets this happened“), sometimes articles are retracted due to errors (see the new Retraction Watch blog), sometimes scientists simply can’t reproduce a result that looked good in the early trials.
[A rule at NEJM prohibiting articles about a drug, written by people with financial ties to the drug] was reversed in 2002, after the journal’s current editor in chief, Dr. Jeffrey M. Drazen, took the job. Dr. Drazen and his colleagues reported that for some subjects, so few experts without financial ties could be found that the journal’s scope was becoming artificially curtailed.(Emphasis added)
Reading The Decline Effect, I thought we were experiencing a weakness of the scientific method. Despite the Seroquel item and the NEJM piece (and others like it), it never dawned on me that we might be experiencing wholesale distortion of scientific research: actively suppressing half the data. Goldacre’s data suggests that perhaps we are.
To paraphrase him: If he tossed a coin 100 times and only reported half of the outcomes, he could convince you – and doctors, and insurance companies, and Medicare, and everyone – that the coin was different than it is. And that wouldn’t be good science.




I invite you to visit my blog, where I have done two recent posts on the problem discussed by Ben Goldacre in the interview: unpublished data in clinical research and the resulting problems of unreliability of the medical literature.
http://marilynmann.wordpress.com/2012/03/25/data-sharing-as-a-moral-imperative/
http://marilynmann.wordpress.com/2012/04/11/more-on-the-need-for-data-sharing-the-tamiflu-example/
Here’s a quote from Harlan Krumholz:
“Every day, patients and their caregivers are faced with difficult decisions about treatment. They turn to physicians and other healthcare professionals to interpret the medical evidence and assist them in making individualized decisions. Unfortunately, we are learning that what is published in the medical literature represents only a portion of the evidence that is relevant to the risks and benefits of available treatments. In a profession that seeks to rely on evidence, it is ironic that we tolerate a system that enables evidence to be outside of public view.”
Krumholz HM. Open Science and Data Sharing in Clinical Research: Basing Informed Decisions on the Totality of the Evidence. Circulation: Cardiovascular Quality and Outcomes. 2012;5: 141-142. http://circoutcomes.ahajournals.org/content/5/2/141.full
Thank you, Marilyn! It’s an honor to have you as a member of SPM – thanks for sharing your work here.
I feel bad when I learn of things our people were working on that I didn’t know about, but then, just as physicians have too much to keep up with, maybe bloggers do too. :)
On a vaguely related note – from today’s NY Times:
Doctor’s Stake in Lab Affects Biopsy Rate –
“Urologists with a financial interest in a laboratory send more prostate biopsies for analysis and have a lower rate of cancer detection than those who use independent labs, according to a new study.”
Upsetting, but I have to confess that I’m not really surprised to discover that there’s a dearth of negative trials outcome reporting. There’s so much money involved in the chase for the New Wonder Drug or New Testing Tech that venality will insert itself into the equation pretty early. And then stay there.
I *love* what Dr. Ben G is doing. Sunlight is an outstanding disinfectant – let’s rip that curtain away and let the sun shine in. Thanks for sharing this!
Updates from a Twitter discussion today:
Theoretically that skewing of published antidepressant studies COULD happen by random chance, in the same way monkeys dancing on typewriters COULD produce Shakespeare; in school we’re taught that each coin toss is unaffected by previous ones.
But then there’s practical reality, in which you ask “C’mon, who are you kiddin’???”. Black Swan author Edwin Taleb discussed this with a tale of “Dr. John” and “Fat Tony.” When Fat Tony sees the coin come out heads 99 times in a row, he knows what’s gonna happen on #100.
For a left-brained statistical analysis, I asked “What ARE the odds of that happening randomly,” and Cardiff GP @AMCunningham dug up GraphPad.com. I’ll insert the table of results in the post above; it says p < .0001 (less than 1 chance in 10,000), “extremely statistically significant.”
Dave- To your comment that p = 0.0001 is extremely statistically significant, there are two caveats:
1. What if the assumptions I used to calculate the p are not valid? This happens all the time. For example, the odds of something never happening in the future that has never happened in the past are not computable (i.e., odds of a national housing collapse, computed in 2007).
2. If I collect one piece of data about each patient in a study and compare the study group versus the controls using that one piece of data, p = 0.0001 is quite significant. Let’s say I’ve got 10 pieces of data (e.g., blood pressure, SF-36 report, complications, hospitalizations… and so on), and I collect that data at 5 visits, and I’ve got 3 doses of my medication that I’m testing (plus a control), and each variable could be studied 10 ways (using numbers, using change from baseline at any visit, using a boolean over/under threshold, after control for demographics, etc). This gives me 1500 different tests, and I only have to report one. If I use a p value of 0.05, the chance that there will be no false positives is essentially zero. Even with a p-value of 0.0001, there is a 14% chance that there will be at least one false positive test that I could report–and that’s assuming that I have been treating the study and control groups identically.
This is the bigger issue: unreported data from a single study. Authors have a choice of saying, “I looked at these data 1500 different ways and found a couple of possibly relevant associations,” and getting rejected, or just reporting the positive associations and having their paper accepted.
This is a big issue because no one runs a large, well-designed and well-funded study and then publishes nothing. Reports of unreported failures are likely fairly over-blown, because if you spend a year or three studying something, you find something publishable in all that data. Look at DATATOP (in Parkinson’s) and the PatientsLikeMe Lithium trial (in ALS) for examples of negative studies that generated great publications anyway. Thus, the problem is that many people don’t report the things they studied that had a negative effect and instead publish the 5 positive findings out of 100 or 1000 relationships investigated without adjusting their p values to reflect unreported comparisons.
Another good factoid is that a p value of 0.01 doesn’t in practice indicate a 1% chance it’s wrong — from a critique of the ESP article last summer:
“Work by Raftery, for example, suggests that p-values in the .001 to .01 range reflect a true effect only 86% to 92% of the time. The problem is more acute for larger samples, which can give rise to a small p-value even when the effect is negligible for practical purposes, Raftery says.”
http://www.sciencemag.org/content/331/6015/272.full?sid=986ee388-d609-407b-925d-db03ce53a6be
It’s very hard to take a statistic like this — there are 45 positive trials and 46 negative trials, but 40 positive trials were published and only 3 negative ones were — and make any conclusions. Mark Helfand of Oregon Health and Sciences University has examined this issue in depth (he’s the editor of the journal Medical Decision Making) and has a great case study with Rofecoxib (Vioxx).
The problem with talking about the number of trials is that some trials are really bad. What if there were 5 studies by specialized sterotactic neurosurgeons on deep brain stimulation and 5 more by non-specialized general surgeons? Could a pharma sabotage a competitor’s product by conducting 25 small-scale studies of their drug where they selected for non-compliant patients?
The key to missing data is when a well-designed prospective study is run but the data that is published is cherry-picked. This is what happened with Vioxx, and actually happens fairly frequently. If I design a study that measures 20 or 30 variables, then I need to choose my p value threshold to be very small. Using a p value of 0.05, there’s only a 20% chance of no false positives if I analyze 30 variables. What’s interesting about this is that the FDA requires that they be sent all the data, and so by reading the long, boring FDA submissions you can actually find this. It won’t be in the journals, though.
With regard to the missing data, there’s a problem of positive publication bias — editors of journals would rather publish positive studies than negative studies, and they would rather publish new studies than confirmation studies, where someone takes another look at a question where the answer has already been published. People try to address this with meta-analysis papers, where they statistically combine all the published studies on something, but unpublished data doesn’t show up in meta analysis anyway.
I think that the solution to this is to separate discovery research from quality analysis, so that people who discover something publish in one set of journals, and people who try and replicate those findings in a real world context publish somewhere else (perhaps Medical Decision Making).
A study that disproves another, prior study certainly belongs in the discovery research journals, but what about one that cast doubt? That’s a lot trickier.
An important point: when I think of the antidepressant research, part of me starts thinking “Does that mean we’ve been hoodwinked and the stuff doesn’t work?” NO – I know several people for whom the drugs are life-changingly effective.
What it means is that we – including physicians, insurers and policy people – haven’t seen all the available evidence. And that interferes with medical science, whose purpose is to improve the solidity of medical advice. (Right? Wrong?)
I did some work with antidepressants and work with people who know them. SSRI’s were conceived through deduction: people felt that low serotonin caused depression and by increasing its availability, they could treat depression. SSRI’s don’t treat depression by increasing availability of serotonin, because serotonin re-uptake is inhibited almost immediately but depression doesn’t abate until about a month later. However, depression is reduced (better than placebo in trials) and so SSRI’s were adopted by induction: an observation of effect that was extrapolated to the general population, although the mechanism is (or at least was, the last time I read up on this topic) unknown.
Ten years ago I was on a discussion forum about the future of science publishing and the internet. Some researchers had a similar complaint: the positive results of research got published and the negative findings didn’t. A few members of the forum hatched the idea of creating “The Journal of Negative Results” that would publish all the residual results of research that didn’t make the journals.
The motive that they gravitated to was helping scientists and funders avoid wasting time and money on approaches to a subject that already had been shown to be fruitless. The chicanery of covering up for weak drugs aside, it’s a egregious waste of resources to repeat research just because nobody knows about it.
I doubt the journal of negative findings has gotten off the ground. I wish Dr Goldacre good luck, but I’m wondering who is going to support and pay for such an idea.
Extremely discouraging, even if the Patient Centered Research Outcomes Institute (PCORI)has said its goal i to truly embed patients into the formation of research questions, which its leadership (especially Dr. Krumholz, above) has pledged to do.
PCORI also has among its committee members John Ionnidis, PhD, whose meta research on medical research in the 1990s exposed the breadth and depth of the problems described here. See an outstanding story of that work from David Freedman of The Atlantic: “Lies, Damned Lies, and Medical Science.” http://bit.ly/zImwm3
It takes a long time to wring such factors out of a money-infused system.
Some additional links:
http://openmedicineeu.blogactiv.eu/2012/05/09/access-to-clinical-data-where-are-the-patient-groups/ (excellent blog by Jim Murray)
http://marilynmann.wordpress.com/2012/05/05/more-commentaries-on-data-sharing/ (another post on my blog with more links)
http://alumni.stanford.edu/get/page/magazine/article/?article_id=53345 (on John Ioannidis)