(A cross-post from susannahfox.com)
I had the great honor of being part of the first Medicine X conference at Stanford University last weekend. I presented a sneak preview of new survey results collected by the Pew Internet Project and the California HealthCare Foundation. Overall, the conference was magical, as I wrote in a previous post.
In this post I would like to explain why I interrupted the HealthTap presentation.

With thanks to Fred Trotter for adapting the original cartoon: http://xkcd.com/285/
Earlier this year, a reporter contacted me to ask about some Pew Internet data that HealthTap was using on the front page of its site and in slide decks. Pew Internet welcomes accurate citation with attribution. That is a common use of our research, whether it is a for-profit, a non-profit, or a government agency making a case for its work.
Unfortunately, HealthTap’s interpretation of a data point was not accurate (more about why in a minute). I wrote to Ron Gutman, founder and CEO of HealthTap, and he responded pretty aggressively that he stood by his own interpretation of the data. I was taken aback. I have never had someone tell me I wrongly interpreted my own data and I wasn’t sure what to do next.
I corrected the reporter’s impression of the data and decided that was the approach I would take if I were asked about it in the future – fact checking on demand.
Here are the facts about our findings: Pew Internet has historically asked a pair of questions meant to measure the broad impact of the internet on health in the U.S. We have asked the questions of all adults, not just internet users. That respondent audience is important, so keep it in mind:
Have you or has anyone you know been HELPED by following medical advice or health information found on the internet? [If they answered yes, the respondent was asked: Would you say the information provided major help, moderate help or minor help?]
Have you or has anyone you know been HARMED by following medical advice or health information found on the internet? [Again, if yes, the respondent was asked a follow-up question: Would you say the information caused serious harm, moderate harm or minor harm?]
Some respondents get the “help” question first in the sequencing of the questions, others get the “harm” question first, to minimize bias.
People who answer “no” to the “help” question represent a population who, at that time, do not know anyone who was helped by information found online. They may have done a health search and found relevant information, but may not feel strongly enough about it to say “yes.” Or they may have looked online for medical advice and not found anything useful. We don’t know. That’s the beauty and the curse of a poll. All we know is the number of people who say the internet has been a help. It is not a question about the internet’s “helpfulness.”
The same goes for the “harm” question. The respondent is asked to recall if they or anyone they know was harmed, not to rate the “harmfulness” of online information.
Our findings have fluctuated over the years, so let’s just look at the data cited by HealthTap, from our report, Chronic Disease and the Internet, which is based on a 2008 national phone survey:
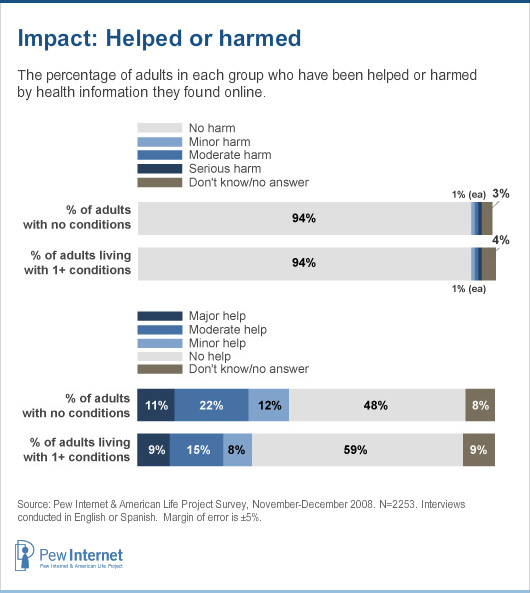
Looking back at this infographic, I have to admit I don’t like it. I can see how HealthTap could interpret it the way they did, emphasizing the “no help” finding.
However, they take it a step farther and imply that people were rating the “helpfulness” of online health information:
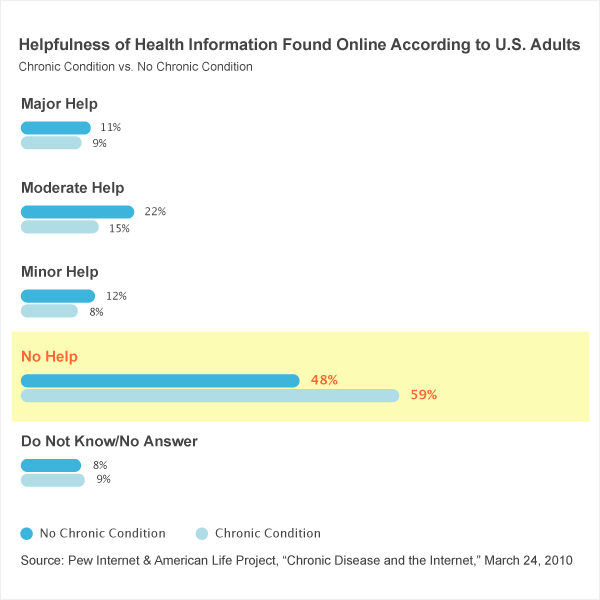
HealthTap’s interpretation distorts the meaning of the question. The people who answered “no” were not saying that the internet was unhelpful. They were in all likelihood saying they do not happen to know anyone who has been helped.
Also, one-quarter of adults in the U.S. didn’t even have internet access in 2008, when this survey was fielded, and 20% of internet users had never looked online for health information. There is simply no way to slice the data to fit HealthTap’s conclusion.
Again, looking back, I don’t like our question. It is too vague. Our infographic does not display the data well. I do not fault anyone for making a mistake and misinterpreting the finding. What is troubling is HealthTap’s refusal to consider my explanation.
Fast forward to Stanford Medicine X.
I have seen Ron talk about HealthTap on multiple occasions and I know the pattern of their pitch pretty well by now. On Saturday, when Geoff Rutledge of HealthTap took the stage, I was interested to learn more about their mobile platform and growing network of doctors. But then the familiar patter began. He was warming up to the same pitch I’d advised Ron to stop making. And there on the screen was the same incorrect table being described as “a recent study from Pew Internet.” I couldn’t let it pass, so I raised my hand and said in a loud voice, “That’s my study and that’s actually not how I would interpret the data.” Geoff paused, said we could discuss it later, and went on to his next point.
I immediately felt bad about interrupting Geoff. It is not my style to be disruptive and, frankly, rude. I took to Twitter to explain myself in the back channel:
- I apologize for the interruption but I have asked HealthTap to stop using that data point. #medx
- Here is the data that HealthTap cites and I disagree with their characterization http://www.pewinternet.org/Reports/2011/Social-Life-of-Health-Info/Part-1/Section-7.aspx
- Note that I think HealthTap is a fascinating model – no argument there #medx
- I feel strongly that we have a responsibility to our survey respondents to be cautious in our interpretation of their answers #medx
Denise Silber, the moderator for the panel, invited me to the microphone before their discussion began so I could explain myself. I apologized, reiterated the points I made in my tweets, and read the questions out loud. I know I went on too long because Denise had to give me the time-out sign. I was obviously wearing my data geek heart on my sleeve that day.
When the session ended, Geoff was very gracious. I have promised to send him a care package of Pew Internet data to replace that slide and I’ll post it publicly, too.
I had a few thoughts and questions to share:
- Pew Internet is going to delete the “help/harm” data points from all future slide decks. These were questions we formulated in the 1.0 era and did not include in the 2012 Pew Internet/CHCF survey – the true kiss of death in research.
- What style of conference is the right one for the health/tech field? The TED-style “sage on stage” who does not take questions? Or the scientific-meeting style of engaged debate? Or is there a place for both?
- Do different rules apply to start-ups? Is it OK to fudge a little bit to make a good point, as one might do in a pitch? Personally, I do not think people are entitled to their own facts. There’s too much at stake.
Two people came to me privately to say that they had gone back over their slides for their presentations on Sunday. They wanted to be sure that every slide, every data point, was fact checked and correct. I still regret the discomfort I caused and felt, but if it sparks a mania for facts in the health/tech arena, it was worth it.
As always, I’d like to hear what other people think. Please share questions and comments (and thanks for reading to the end of this very long post).




Trackbacks/Pingbacks