This is a complex post, so don’t jump to any conclusions.
Two weeks ago (gad, was it that long?) I asked you to think about something for a few days:
Imagine that for all your life, and your parents’ lives, your money had been managed by other people who had extensive training and licensing. Imagine that all your records were in their possession, and you could occasionally see parts of them, but you just figured the pros had it under control.
Imagine that you knew you weren’t a financial planner but you wanted to take as much responsibility as you could – to participate. Imagine that some money managers (not all, but many) attacked people who wanted to make their own decisions, saying “Who’s the financial planner here?”
Then imagine that one day you were allowed to see the records, and you found out there were a whole lot of errors, and the people carefully guarding your data were not as on top of things as everyone thought.
Two weeks before that post, I’d had a personal breakthough in my thinking. For a year I’d been a rabid enemy of Google Health, but now I said: I’m putting my data in Google and HealthVault: “I’m concluding that we can do more good by aggregating our data into large, anonymized databanks that smart software can analyze to look for patterns. Early detection means early intervention means fewer crises.” And I observed that the power of Web 2.0 “mash-ups” …
…lets people create software gadgets without knowing how they’ll be used, it lets people build tools that use data without knowing where the data will come from, and it lets people build big new systems just by assembling them out of “software Legos.”
So, I said, “I’m in.” I decided to punch the big red button and copy my personal health data into Google Health. What happened is the result of PatientSite’s “version 1” implementation, not their eventual full implementation, of the interface. To my knowledge, zero or one other hospitals have any interface at all, and as I’ll say later, I’m not even sure how much of the Google Health side of the connection is complete. Nonetheless, what I learned about my own data was quite informative, and quite surprising. (I’ve discussed what follows with hospital staff; this isn’t gossip behind anyone’s back. IMO, empowered people don’t gossip, they communicate clearly and directly with the people involved.)
When Google Health launched last May, my hospital’s CIO blog said “we have enhanced our hospital and ambulatory systems such that a patient, with their consent and control, can upload their BIDMC records to Google Health in a few keystrokes. There is no need to manually enter this health data into Google’s personal health record, unlike earlier PHRs from Dr. Koop, HealthCentral and Revolution Health.” So I went into my patient portal, PatientSite, and clicked the button to do it. I checked the boxes for all the options and clicked Upload. It was pretty quick.
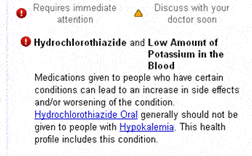
 But WTF? An alarm: “! Requires immediate attention” [see screen capture at right]
But WTF? An alarm: “! Requires immediate attention” [see screen capture at right]
Okay, yes, HCTz is my blood pressure medication. But low potassium? That was true when I was hospitalized two years ago, not now. What’s going on?
Then I saw the list of “conditions” it told Google I have. At left is a partial screen grab, and at right is the complete condition list that PatientSite transmitted: (Spoiler alert; this stuff is biological and might seem gross.)

Acidosis Anxiety Disorder Aortic Aneurysm Arthroplasty - Hip, Total Replacemt Bone Disease CANCER Cancer Metastasis to Bone Cardiac Impairment CHEST MASS Chronic Lung Disease Depressed Mood DEPRESSION Diarrhea Elevated Blood Pressure Hair Follicle Inflammation w Abscess in Sweat Gland Areas HEALTH MAINTENANCE HYDRADENITIS HYPERTENSION Inflammation of the Large Intestine Intestinal Parasitic Infection Kidney Problems Causing a Decreased Amount of Urine to be Passed Lightheaded Low Amount of Calcium in the Blood Low Amount of Potassium in the Blood Malignant Neoplastic Disease Migraine Headache MIGRAINES Nausea and Vomiting Nephrosis PSYCH Rash Spread of Cancer to Brain or Spinal Cord Swollen Lymph Nodes
Yes, ladies and germs, it transmitted everything I’ve ever had. With almost no dates attached. (It did have the correct date for my very first visit, and for Chest Mass, the x-ray that first found the undiagnosed lesion that turned out to be cancer. But the date for CANCER itself, the big one, was 5/25/07 – four months after the diagnosis. And no other line item had any date. For instance, the “anxiety” diagnosis was when I was puking my guts out during my cancer treatment. I got medicated for that, justified by the intelligent observation (diagnosis) that I was anxious. But you wouldn’t know that from looking at this.)
See how some of the listed conditions have links for More Info?  Let’s see, I was diagnosed with optical migraine. (I diagnosed myself, actually, by researching my symptoms and finding this illustrated site. That’s what e-patients do; it saves time in the doctor’s office… I brought a printout, with a dated list of episodes.) But optical migraine is not the impression you’d get from reading my Conditions list – in fact during my cancer workup one resident said “But you have headaches, right?” “No,” I said – “optical migraines, but without pain.” (Update 4/2: the illustration at left shows the dazzling pattern that an optical migraine produces.) So for that item in the conditions list, I clicked More Info. I didn’t get more info (i.e. accurate info) about my diagnosis, just Google’s encyclopedia-style article about migraines in general. (An optical migraine has little in common with migraines in general.)
Let’s see, I was diagnosed with optical migraine. (I diagnosed myself, actually, by researching my symptoms and finding this illustrated site. That’s what e-patients do; it saves time in the doctor’s office… I brought a printout, with a dated list of episodes.) But optical migraine is not the impression you’d get from reading my Conditions list – in fact during my cancer workup one resident said “But you have headaches, right?” “No,” I said – “optical migraines, but without pain.” (Update 4/2: the illustration at left shows the dazzling pattern that an optical migraine produces.) So for that item in the conditions list, I clicked More Info. I didn’t get more info (i.e. accurate info) about my diagnosis, just Google’s encyclopedia-style article about migraines in general. (An optical migraine has little in common with migraines in general.)
The really fun stuff, though, is that some of the conditions transmitted are things I’ve never had: aortic aneurysm and mets to the brain or spine. So what the heck??
I’ve been discussing this with the docs in the back room here, and they quickly figured out what was going on before I confirmed it: the system transmitted insurance billing codes to Google Health, not doctors’ diagnoses. And as those in the know are well aware, in our system today, insurance billing codes bear no resemblance to reality. (I don’t want to get into the whole thing right now, but basically if a doc needs to bill insurance for something and the list of billing codes doesn’t happen to include exactly what your condition is, they cram it into something else so the stupid system will accept it.) (And, btw, everyone in the business is apparently accustomed to the system being stupid, so it’s no surprise that nobody can tell whether things are making any sense: nobody counts on the data to be meaningful in the first place.)
It was around this time that I commented on Ted Eytan’s blog, “when you’re exporting to a new system, the rule is, Garbage Out, Garbage In. (Hint: visibility into the data in your old system may leave you aghast.)” We could (and will someday) have a nice big discussion about why the hell the most expensive healthcare system in the world (America’s) STILL doesn’t have an accurate data model, but that’s not my point. We’ll get to that.
And now we get to why I said, at the outset, don’t jump to conclusions. I’m mildly bitching about PatientSite, but that alone wouldn’t justify staying up to 3 in the morning all night writing a 2800 3500 word post; that one system isn’t a big deal for e-patients everywhere. (And besides, although PatientSite is old and clunky, a 1999 system if I ever saw one, it beats what most hospitals offer, and it did the job very well for me during my illness. And this is just version 1 of the interface; the current folly is not a permanent situation.)
The BIG question is, do you know what’s in your medical record? And THAT is a question worth answering. For every one of you.
See, every time I speak at a conference I point out that my 12/6/2003 x-ray identified me as a 53 year old woman. I admit I have the man-boob thing going on, but not THAT much. And here’s the next thing: it took me months to get that error corrected, because nobody’s in the habit of actually fixing errors. Think about THAT.
I mean, some EMR pontificators are saying “Online data in the hospital won’t do any good at the scene of a car crash.” Well, GOOD: you think I’d want the EMTs to think I have an aneurysm, anxiety, migraines and brain mets?? Yet if I hadn’t punched that button, I never would have known my data in the system was erroneous.
And this isn’t just academic: remember the Minnesota kidney cancer tragedy just a year ago, which arose at least partly out of an error that ended up in the hospital’s EMR system. Their patient portal allowed patients and family to view some radiology reports, but not the one that contained the fateful error.
The punch line came when I got over my surprise about what had been transmitted, and realized what had not: my history. Weight, BP, and lab data were all still in PatientSite, and not in Google Health. So I went back and looked at the boxes I’d checked for what data to send, and son of a gun, there were only three boxes: diagnoses, medications, and allergies. Nothing about lab data, nothing about vital signs.(So much for “no need to manually enter this health data into Google’s personal health record.”) And of the three things it did transmit:
- what they transmitted for diagnoses was actually billing codes
- the one item of medication data they sent was correct, but it was only my current BP med. (Which, btw, Google Health said had an urgent conflict with my two-years-ago potassium condition, which had been sent without a date). It sent no medication history, not even the fact that I’d had four weeks of high dosage Interleukin-2, which just MIGHT be useful to have in my personal health record, eh?
- the allergies data did NOT include the one thing I must not ever, ever violate: no steroids ever again (e.g. cortisone) (they suppress the immune system), because it’ll interfere with the immune treatment that saved my life and is still active within me. (I am well, but my type of cancer normally recurs.)
In other words, the data that arrived in Google Health was essentially unusable.
And now I’m seeing why, on every visit, they make me re-state all my current medications and allergies: maybe they know the data in their system might not be reliable.
Hey wait, a new article in the Archives of Internal Medicine (co-authored by our own Danny Sands, my very own primary) says Clinicians override most medication alerts. Could it be they’ve been through this exercise themselves, and they consider the data unreliable? (Or do they just not trust computers?) (Hey Pew Internet, wanna check for generational differences?) Who knows, perhaps the resident in the migraine story has learned early on that the data in his system is not to be taken at face value – I don’t know.
In any case, my hospital is very proactive and empowering to staff about root cause analysis for failures, with its “SPIRIT” program, and they’ll add any process or form that can catch potential errors. That’s good. But wait: On numerous visits, I’ve restated on those forms “no steroids.” But evidently what I write on the forms never gets entered into the system. Hm.
I work with data in my day job. (I do marketing analytics for a software company. We import and export data all the time.) I understand what it takes to make sure you’ve got clean data, and make sure the data models line up on both sides of a transfer. I know what it’s like to look at a transfer gone bad, and hunt down where the errors arose, so they don’t happen again. And I’m fairly good at sniffing out how something went wobbly.
And you know what I suspect? I suspect processes for data integrity in healthcare are largely absent, by ordinary business standards. I suspect there are few, if any, processes in place to prevent wrong data from entering the system, or tracking down the cause when things do go awry.
And here’s the real kicker: my hospital is one of the more advanced in the US in the use of electronic medical records. So I suspect that most healthcare institutions don’t even know what it means to have processes in place to ensure that data doesn’t get screwed up in the system, or if it does, to trace how it happened. Consider the article in Fast Company last fall, about an innovative program at Geisinger. Anecdotally, it ended with this chiller:
“… a list of everybody that accessed the medical record from the time he was seen in the clinic to two weeks post-op.’There were 113 people listed — and every one had an appropriate reason to be in that chart. It shocked all of us. We all knew this was a team sport, but to recognize it was that big a team, every one of whom is empowered to screw it up — that makes me toss and turn in my sleep.”
In my day job, our sales and marketing system (Salesforce.com) has very granular authorizations for who can change what, and we can switch on a feature (at no extra cost) to track every change that’s made on any data field. Why? Because in some business situations it’s important to know where errors arose – an error might cause business damage, or an employee might sue over a missed quota.
So I’m thinking, why on earth don’t medical records systems have these protections? If a popular-priced sales management system has audit traces, to prevent an occasional lawsuit over a sales rep’s missed commission, why isn’t this a standard feature in high-priced medical records systems? In any case, in the several weeks since these discoveries started, as far as I know they haven’t figured out how my wrong data got in there. And without knowing how the wrong data got in, there’s not a prayer of identifying what process failed.
BUT AS I SAID, this is not about my hospital; a problem at my hospital affects only one scrillionth of patients in the US, not to mention the rest of the world. And please don’t blame my hospital’s CIO; I think what he wrote about the Google Health interface was overzealous, but I believe he’s a good man, committed to helping us own our own data (his work on the Google Health advisory board was unpaid), and this post isn’t about him: as far as I know, this hospital is farther along than anyone else: hardly anyone else has implemented a Google Health interface. (Perhaps for good reason.) Nor is this a slam on Google Health.I haven’t probed yet into whether there are limitations in what it does; might be fine, might not. Heck, neither PatientSite nor I have put any good data into it yet. (And I haven’t even touched HealthVault.) None of that is my point. Rather, my point is about the data that was already in my PHR, uninspected. For that, let’s return to my previous post:
Then imagine that one day you were allowed to see the records, and you found out there were a whole lot of errors, and the people carefully guarding your data were not as on top of things as everyone thought.
In my day job, when we discover that a data set has not been well managed, we have to make a decision: do we go back and clean up the data (which takes time and money), or do we decide to just start “living clean” from now on? My point, my advice to e-patients, is:
- Find out what’s in your medical record. What’s in your wallet, medically speaking? Better find out, and correct what’s wrong.
- Get started, manually, moving your data into Google Health, HealthVault, or some such system. I’ve heard there are similar PHR systems (personal health records), not free but modestly priced, that can reportedly make this easier. I’m sure their friends will show up here in the comments. (Feel free to post product info links in the comments, everyone.)
- Let’s start working, now, on a reliable interoperable data model. I know the policy wonks are going to scream “Not possible!” and I know there are lots of good reasons why it’s impossibly complex. But y’know what else? I’ve talked to enough e-patients to be confident that we patients want working, interoperable data. And if you-all in the vendor community can’t work it out, we will start growing one. It won’t be as sophisticated as yours, but as with all disruptive technologies, it will be what we want.And we’ll add features to ours, faster than you can hold meetings to discuss us.I have to say, while researching this post I was quite surprised at how very, very far the industry has to go before reaching a viable universal data model. New standards are in development, but I’m certain that it will take years and years and gazillions of dollars before any of that is a reality. (What, like costs aren’t high enough already?) In the meantime, your data is probably not going to flow very easily from system to system. Far, far harder than (for instance) downloading your data to Quicken from different credit card companies and banks. (Wizards and geeks refer to this “flow” issue as “data liquidity.” We’ll talk about that in the future.)
- Let’s start working, now, on an open source EMR/PHR system. The open source community creates functionality faster, and more bug-free, than commercial vendors do – and nobody can latch onto proprietary data in such systems to milk more margin out of us… because it ain’t proprietary.The great limitation of open source is that it’s generally not well funded. But you know what? Every person in America (including software engineers) is motivated to have good reliable healthcare systems, and I assert that the industry ain’t getting’ it done on their own. As I said in my Thousand Points of Pain post (cross-posted on IBM’s Smarter Planet blog as A business thinker asks, what will it take to get traction?), it’s fine with me if industry vendors come along too – but I would not stake my life on their moving fast enough for my needs. Or your mother’s needs.
Want a case study with real consequences? Recall what happened last year to famed Linux guru Doc Searls when he couldn’t read his own scan data, because good cross-platform image viewing tools weren’t available. (His prescription: the patient should be the platform and “the point of integration.”) Well, okay, so Doc was a year ahead of me. I’m catching on. This illustrates why I think people from outside the profession may be our greatest asset in building what patients really need: patients tend to build what they want. And we who work with data all day know that these problems are not unsolvable.
My bottom line: I think we ought to get our data into secure online systems, and we shouldn’t expect it to happen with the push of a button. It’ll take work. So let’s get to work. You know the work will be good for you, and heaven only knows what you’ll learn in the process. You’ll certainly end up more aware of your health data than when you started. And that’s a good thing.
Minor edits made 4/12/2009, and 1/5/2012 and 9/19/2022 for clarity and to adjust to this blog’s new format




Fantastic article
It makes you wonder what the hospital’s EMR looks like.
And it is obvious that the patient needs visibility into the data.
We as ICMCC have proposed a guideline to the WHO on Record Access and the right to make corrections.
http://recordaccess.icmcc.org/category/WHO.
Lodewijk
Lodewijk, what was the outcome of your proposal? (It’s worth a quick read, folks!)
Dave: I loved reading your recent post on discovering what’s in your medical record. People must start to understand that medical records, both paper and electronic, are mostly useless (and sometime incorrect) data, and not much information. This is especially true when you get sick, and then stuff happens, and all of these data start to flow.
It used to be that these data were in paper charts. If I admitted a patient to the hospital, I’d ask for old records to be sent to the floor (funny word for the unit in the hospital where my patient was located). And, like as not, this 3-4 inch thick folder would appear, or sometimes several of these.
Part of being a doctor consists of learning how to locate the INFORMATION in this huge collection of DATA, most of which is completely irrelevant now, although it might have been relevant at some earlier date.
And so, you start by compiling the relevant data into a new set, something that goes like this: Ok, here’s a list of current diagnoses and a few past conditions that need to be kept in mind. Let’s exclude all the old or wrong diagnoses, and try to keep the list fairly short; here’s the list of medications that she’s currently taking, and an allergy or two….got to get this right because I don’t want to stop something important or continue a drug that isn’t being taken any longer; fine…now I need the vital signs for the past 24 hours, or maybe the last couple of days; … and I need the lab tests that pertain to current medical problems, e.g. diabetes, or anemia, or cancer; got it…ok, now let’s consider family history, procedures that have been done, and social history; need to know if she still smokes cigarettes and has remarried, anything new with the kids; and don’t forget advance directives, should something awful happen…does she want to be a “code blue” or be tube fed?
It’s only when you have this “handle” on the patient as she is today, that you can start to approach the new problems that have presented and are the cause for the new hospitalization (or clinic visit).
And so on. The Continuity of Care Record, CCR, standard, started out life as this summary of relevant patient information AT A PARTICULAR POINT IN TIME. Clearly, the integrity of the information, and its accuracy, would be very important. We thought of it as a “snap shot” of a person’s most important and relevant health information.
Fast forward from 2003, when the CCR standard was first created, to your experience with the hospital records being dumped into Google Health. It’s sort of like taking that 4 inch think paper chart and dumping the contents — imagine words and letter and numbers falling out of the pages — into a small measuring cup. It overflows and dribbles onto the floor, and who the heck knows the value of what you’re holding in your hand?
No, no. That won’t work. The hospital, the doctors, or someone knowledgeable needs to go through your medical records with a filter BEFORE they send all of that useless data to Google Health or your PHR from Health Vault. Someone, perhaps with your involvement, needs to APPRAISE the value of the information and DETERMINE its relevance to the next possible visit or encounter or use of these data for your health care.
I hope you’ll keep telling this story. It made me laugh and cry at the same time.
Your friend, DCK
Nothing like a lightning bolt of reality to shake up the insanity of U.S. healthcare, health IT included.
A lot becomes clear when one real incident, like Dave’s, bumps into the myth. I suspect most citizens think those huge IT systems at hospitals and health care systems are accurate, comprehensive, and sophisticated. Uh, nope. They are games and PR mostly based on and in service of our health insurance system.
I have seen 30 years of huge IT projects that burned millions or billions of dollars and produced nothing. I have seem open-access software produce the best solutions we have. IBM sells Apache servers. Sun Microsystems sells MySql. ‘Nuff said.
Unfortunately, Obama’s $17 billion for health IT shows little promise for being anything other than a taxpayer bailout for technology dinosaurs, or worse, that elite segment that shuffles bad data between insurance companies and hospitals so the shuffler, hospital, and insurance company can make a lot of money while 98,000 Americans die from medical mistakes each year. (That could probably be 75,000 to 300,000, but you get the point.)
So, how does this open access project get started? And, jeeze, couldn’t some of that $17 billion go to the people that do the work?
Dave,
when we put it together ICMCC was a relatively unknown organisation. Just sending it to them would not have worked. This needs its proper procedure and its proper trajectory to reach the right level.
But through proper channels it has reached Margaret Chan of the WHO about a month ago.
So let’s see what comes out of that.
Any support from (national) delegations to the WHO would of course be much welcome.
I myself have no chops in the open source community but I know @Modulist is in touch with Joe Cerro @Cerro who is organizing a HealthCamp Boston for 4/21, the day before Health 2.0 / Icks. @Modulist claims to have done some substantial OS-based projects for MIT and Harvard and as just recently gotten turned on to healthcare, and seems well grounded in all the data crap we’re discussing here. I talked to him last night and he too observed “These problems are not unsolvable.”
Time will tell. Thanks to all the great support from everyone.
(David, I can barely express how it feels to hear your feedback. Hearing “I laughed, I cried” is just way too much fun! :–) It’s not the kind words as much as it is the affirmation that the work we’ve done here this past year has moved in apparently the right direction.)
And now the work begins.
And therein lies the absurdity from trying to integrate today’s technology into 1985-based proprietary pieces of dung cobbled together with 25 years of bazooka bubblegum billing machines. Thank you Dave. You rock my world. This will be linked to and referenced in all of my talks for many years to come. See you in Boston in April.
When a patient presents that doesn’t speak the doctor’s language a translator is called in at great effort and expense. Yet that same doctor doesn’t insist that their EMR accept a standard CCR.
Things would be very different if your doctor felt some responsibility for _using_ the information in your Google Health account. Maybe you’re not paying him enough? In our fee-for-service system, care coordination is not reimbursed and the doctor’s EMR has no provision for viewing or importing data from a patient-centered medical home account. As it is, the system seems designed to punish you for straying outside of the integrated delivery network.
Google Health is doing their part by taking and giving you a CCR on the wire. The doctors, hospitals and EMR vendors seem to be waiting for someone to show them the money.
Simply reading this story has induced in me some of the the very same conditions you apparently have had yourself. Including:
Anxiety
Depressed Mood
Diarrhea
Elevated Blood Pressure
Lightheaded
Migraine Headache
Nausea and Vomiting
Hair Follicle Inflammation w Abscess (well,maybe not this one)
Thanks for sharing you experience.
I find Dr. Gropper’s comment just amazing! Makes me think once again that healthcare reform should never be put in the hands of healthcare professionals.
Dave just talked about a real experience demonstrating the multiple points where the system COMPLETELY breaks down and Dr. Gropper can only attribute the problem of this brain-dead system to an issue of reimbursement. It has nothing to do with reimbursement and all to do with the lack of depth of the data stored and transmitted.
The PHR research sponsored by RWJF has already shown that PHRs are basically useless if you do not integrate the cold, hard data with ODLs. If you do not provide real means to put all data elements of an EHR in context you’ll end up having a very dangerous tool that will probably cost even more lives than nocosomal infections.
Good medecine is never just about money and always about complex human interactions. Unless EHR/PHR are designed to include accurate recordings of these interactions, they will never be able to provide the means to obtain valid contextual data. That’s why Dave post is so important.
Dave,
If it weren’t so sad I would say what a great story. Thanks for sharing this. It points out exactly where thing go wrong.
Your analysis is razor sharp and I completely agree with your advice to e-patient.
There might be one thing you have to add: the mean reason why all initiatives in a new direction are hindered.
As you put it Garbage out means Garbage in. Knowing the things that you nicely illustrated in your article, basically means that we have to discard all data that is stored today and start all over again. This time with systems that support semantic interoperability, have granular access control, audit trails, etc., etc.
This is what we call the ‘Greenfield solution’. As you probably can imagine this is not your typical favorable solution for those parties who have been using these ‘legacy systems’ (basically everybody who is involved in healthcare today). Especially since the legacy systems themselves also have to be replaced with modern systems, the vendors of legacy systems are also in the resistance mode. They first want to see their return on investment (and a new business model) before they move ahead.
I’m actively involved in an open standard/ -source community (openEHR) who has been for the past 15 years (and still is) doing exactly what you recommend:
– Let’s start working, now, on a reliable interoperable data model.
– Let’s start working, now, on an open source EMR/PHR system.
This jointed effort has resulted, among other things, in a reliable interoperable data model, which already has gone through the process of international standardization. This has recently leaded to the international accepted EN/ISO 13606 (EHRcom) standard.
On top of this the openEHR community has developed reference implementations and several open source solutions which all can be freely downloaded through our website (www.openehr.org). With information systems based on openEHR it becomes possible to address those access, permission, audit and quality issues you’ve mentioned. Sadly it turns out that being available is not enough. Besides several academic groups (all over the world) and a (quite a) few private initiatives, nobody is currently using it in a hospital or other traditional clincal setting.
So if it’s all there. Why isn’t it being used then? To make a long story short: because the citizen/ client/ patient/ customer doesn’t ask for it or to be more precise: doesn’t demand it.
As long as we citizens allow our healthcare providers to produce and use Garbage when it concerns our health and healthcare, not much will change. Since healthcare provider have to invest a lot of time and money to clean up their Garbage and then have to invest in new information systems, they won’t do that unless they either get paid or somebody forces them to do that.
Since nobody seems to be wiling to pay we (the citizen) have to demand for changes in order for them to happen. I’m confident that great initiatives such as e-patient will make sure that that will happen.
Best regards,
Stef Verlinden
Stef,
Well, isn’t that fun: I recommended something you (plural) have been working on for years. :–) Good to meet you! Give us some links!
Dave,
Good to meet you too.
Although it remains complex material (it can’t be explained in 3 sentences and it’s not really sexy. That’s the other main reason why people back off:-) ), here you can find a ‘primer’ about openEHR. In this article the pitfalls of a semantic interopable and juridico-legal sound EHR and the solutions provided by the community are briefly touched: http://www.openehr.org/shared-resources/getting_started/openehr_primer.html
From there on one can go ‘as deep’ as desired, including the download of the complete source codes.
My personal interest is in semantic interopable PHR or shared health record as I call them today: http://vivici.wordpress.com/2007/10/26/a-personal-health-care-record-phr-based-on-international-open-standards-facilitates-true-patient-empowerment/
Best regards,
Stef
Dave:
Bravo. Bravo to you for holding your nose and leaping in.
This is without a doubt the most important blog I have ever read.
Dave, Your article highlights some of the key dilemmas in thinking about what is your health record and what does it mean to make it portable. I do think there’s one contradiction, though, and it has to do with whether you want all of the data sent in all of it’s rawness and irrelevance, or do you want it managed on your behalf and only have what someone else judges to be relevant at this point sent? The discussion about duplicate diagnoses and irrelevant diagnoses (because absolutely transitory), as well as current vs historical medications raises fascinating questions that might be easier to resolve if you were getting snapshots of your data all along the way, rather than in one big historical lump.
Jan
Dave,
Fascinating post; I was too naive to imagine that export of clinical data would also include some outcome references like a discharge date or comments for a specific condition.
Did you share your findings with Dr. Halamka or the people at Google Health? What do they have to say on your experience?
Robert
Robert,
Yes, as I said in the post, I discussed this with hospital staff, and that includes Dr. Halamka. I’d prefer not to speak for him – it’s a complex subject and I’d rather let him speak for himself.
As far as I know, Google Health isn’t even part of the equation at this point because, as I noted: “I haven’t probed yet into whether there are limitations in what Google Health] does; might be fine, might not. …neither PatientSite nor I have put any good data into it yet.”
Hi Lois – not to be too naive, but what has you say this is the most important blog you’ve read? (Did you mean this post or the whole blog in general?)
This is cross-posted from a response I made on THCB. Someone (I’ll leave it to her to speak up here if she wants) suggested it should be the hospital’s job to clean up the data.
====
I don’t disagree, but consider that hospitals may not have the ABILITY to clean up the records. There may be no way to tell which data are correct and which aren’t.
Also consider what it would do to healthcare costs if we mandated that hospital staff comb through all their medical records and verify everything. This is what I alluded to when I said that in my day job we sometimes face the question, is it worth the time and money to go back and clean it up, or should we just mark the old data as uncertain and start “living clean” from that moment forward?
This is a real-world challenge in my day job, where the stakes are much lower. (In my job, getting a customer’s phone number wrong in our customer database generally doesn’t lead to death.)
I know first-hand, when you look at a piece of questionable data, it’s more or less a “state function”: it says what it says, and there’s no way to tell how it got that way. And if you can’t trust the integrity of the PROCESS that got it there, there’s no way to know if it’s reliable: you just have to go check.
In other words, you essentially throw it out and start over.
======
Dave,
you’ve spoken of John Halamka & GoogleHealth. But NOBODY has mentioned CCHIT yet. You should become THE case study for CCHIT and I strongly believe you should be nominated to be the first real patient representative in its Personal Health Record (PHR) Advisory Task Force.
You have masterfully demonstrated what happens when healthcare professionals design systems for patients without any direct & continuous input from the informed patients. Hopefully this will change fast, now that we see that it just doesn’t work.
Someone on THCB said, about records that you and I can edit: “I don’t see how a physician can rely 100% on such records.”
This shines a brilliant spotlight on what we’re calling Participatory Medicine. It’s like what’s expressed in an NEJM article we discussed here, about Physicians as Coaches, Patients as Players.
The newly formed Society for Participatory Medicine exists to develop and publicize best practices in how to make Tom Ferguson’s e-patient principles a functioning reality, and the new Journal of Participatory Medicine will publish articles and research about it. The Facebook page says:
Most of the Society people, including many Journal board members, will be gathering for the first time at the Health 2.0 / Ix conference in Boston 4/22-23, and many may attend the pre-conference event 4/21 “HealthCamp Boston” that’s being informally organized on Twitter with the hashtag #hcbos.
I think the idea of “can a doctor *rely on* this data” presumes that the doctor will be a separate party, almost in a separate room, assessing information in isolation from the patient. This is a dying model; in the new world, we collaborate, it’s participatory. The doctor is no longer required to assess data in isolation and come up with the right answer or be beaten on the head by the Chief; the doctor actually talks with the patient, looking at the same data at the same time (as my doc does with me), and say “What’s with this?”
Surely the Society we’ll need to develop best practices for who’ll change what when. Hey, here’s an idea from the business world: Maybe Google Health will offer an audit trail, as Salesforce.com does, to see what got changed when – including the ability to roll back the database to the last known good version. What would you think in that case?
This post gives so much texture to a problem that is all too real. We need to develop standards to address the brave new world of e-health.
Dave, thanks so much for an amazing, enlightening, and frightening post. Really disheartening–no short-term stuff like labs or vitals, and no detail for chronic stuff like expected on a PatientsLikeMe type site. Hard to see how EMR like this will be useful for individuals or for greater good.
– Kevin
Kru Research
Dave,
This is by far the best capture of the issues I’ve ever seen. It is medical ethnography, written by an extremely articulate participant-observer: You.
I agree w/ so many comments your readers have offered. Especially, with Gilles Frydman’s comment that, “You have masterfully demonstrated what happens when healthcare professionals design systems for patients without any direct & continuous input from the informed patients.”
Direct, continuous input is the key; it’s the fastest route to value – commercial and otherwise – for all invested in reform.
Keep raising the bar. We can get this done!
I want to draw everyone’s attention back to David Kibbe’s comment way back at the top:
In light of all your comments, David’s remark now rings with great wisdom: it’s about the information, and the data has value only to the extent that it conveys information. When data is used perversely to convey different information than what it was created for, the whole system turns into shaky pudding.
It’s analogous to using one size of nut on a bolt of a different size: it can LOOK like things are right, when they’re not. And literally, plane crashes can happen.
Honestly when I wrote this I had no idea what I was starting. My motivation was simply to alert e-patients to what they/we need to know, so we can be responsible for our own health. That’s a fundamental tenet of participatory medicine: the physician may be our expert consultant, but we’re the ones on the playing field, we’re the ones in the game.
So to me, as David says, it’s the information that matters. At work all I really know is that I have a job to get done, like figuring out which customers have been in touch within the past two years, or figuring out which of our ads get the most response. And the data has to be reliable, collected accurately and not messed with, so I can be sure I’m getting reliable answers, on which I can then base good decisions and get good results.
Otherwise my sales team might call the wrong person, or I might nag a sales rep about something that’s not actually a problem, or we might spend more ad money on something nobody’s been responding to. Common sense, right?
See, anyone can understand that data that doesn’t convey accurate information causes problems in the simplest business situation.
So why is it a mystery that it’s VITAL for our MEDICAL data to be accurate?? It’s really, really, really important for medical data to be accurate, or, as David says, it conveys no good information.
The wrong kidney might get taken out. A treatment might be passed over because it’s contraindicated for migraine headaches, when I didn’t have migraine headaches. And so on and so on.
And I’ll tell ya, if there aren’t processes in place to control how the data gets into a system and what gets done to it, the resulting data will be crap. You won’t be able to rely on it for anything, because the data won’t convey reliable information.
After chasing zebra’s for 7+ years, we learned how to keep our own records. Working with multiple doctors with multiple ideas that never communicated was a learning experience.
After dealing with them for years, I can see why the information can be garbage. Some of them just don’t listen to what you tell them. They have it in their mind what is wrong and after the first 2 minutes, nothing you say is going to get them off track.
That garbage followed me around as I went to doctors in the same network. At least then I could read my file. Now, it is locked up in a computer and I have no idea how to look at it. I’m all for electronic medical records…as long as the patient has access.
Dave,
Just catching up to your post and so much intelligent response and input (with the requisite flies in the ointment, too). There are almost too many facets to get my arms around.
I’m one of those patients who suffered from bad record keeping, not transferred correctly, resulting in a dx of a deadly cancer which, as it turned out, I never had. Had I not gotten copies of my records and begun piecing together the mistakes that were made (googling every other word because I had NO idea what any of it meant) I might have died from chemo I didn’t need.
The brave new world of functional EMRs is years away, but patients are getting sicker and dying from faulty records today. While the “experts” sort out how EMRs will happen — and WORK — I’m preaching to patients about getting copies of all their records, reviewing and questioning them when there are errors. They need to get them from their providers AND if they find mistakes they need to correct them. In addition to correcting mistakes, they need to follow up with the Medical Information Bureau to be sure those errors haven’t taken on a life of their own.
For plain old non-medical-professional-type patients who might read this post, here’s information to help:
How to Get Copies of Your Medical Records
How to Correct Errors on Your Medical Records
The Medical Information Bureau
I’m so pleased to know so many of you will be at Health 2.0 — I am in awe. Can’t wait to meet you all.
Listen to what Trisha said, people. Trisha is the patient advocate whiz on About.com, and a strong e-patient herself, with lots of real-world experience. And she says:
“patients are getting sicker and dying from faulty records today.”
Regardless of what you think about Google Health, get your records and check them.
Dave,
you asked why it is a mystery that it’s vital for medical data to be accurate. But in some ways it is completely accurate. It all depends where you want the accuracy to be.
I repeat that your story should become THE CASE STUDY for everyone involved in building and managing EHRs/PHRs. I say that because your story demonstrate to the nth level how dysfunctional the medical system has become. I do not believe that anyone involved in providing medical care or medical data services in hospital systems and private practices has any doubt that they constantly carry erroneous data. The system literally demands that they carry erroneous data in order to be reimbursed. And so they have carried that erroneous data for years and years and EVERYBODY knowingly winks because it is well known that’s the only way to get paid/reimbursed. How sick is a system that forces its professionals to consciously write erroneous data and then hides this simple fact under total silence. You’ve just surfaced a “secret de polichinelle” (an Open Secret) for the healthcare professionals.
In truth, until the advent of GoogleHealth and HealthVault this systematic behavior had no negative consequences, since the data was only shared for pecuniary reasons.
Now, all of a sudden, these software powerhouses are bringing real disruption into the system. Interestingly enough, I don’t believe that anyone expected the kind of problems you have demonstrated. Or if they did they all kept very silent about it for years while preparing the common framework for PHR that was produced by the Markle Foundation with the input of all major EHR/EMR vendors, producers, users and payors.
While we were blinded by the obvious privacy risks associated with cloud-based PHRs it looks like we missed the more profound effect of the law of unintended consequences. As Matthew said, this is a really, really important story.
If the American medical system was no longer a fee-for-service but a performance based system I think many of the issues you have discovered would subside over time, since pay-for-performance requires follow-up over time and therefore require to put all data in context. Just remember that in Denmark 98% of private practices have an integrated EHR, that the patients own their data and that the annual cost/patient is under $1!
Dave’s original post and the comments have been enlightening. I love how one dose of reality, like Dave’s data transfer from his health care provider’s medical record to Google Health brings so much into sharp focus. We see the same type of thing happen at The Serano Group when we tell people what typically happens if you go to an MD and tell them you have a positive test for Lyme borreliosis. Some even probe their own doctor, not believing what we tell them. Not until the abrupt reality of your friendly family doctor suddenly treating you like you are an incipient terrorist, or worse, just because you ask a few questions, do you realize the absurdity of how medicine handles persistent infections.
But back to Dave—what did we find out from all this? Medical records are mostly a joke as confirmed by David Kibbe. As Gilles noted, some doctors, god love ‘em, can take any complex problem and reduce it to, “Why can’t I get paid more and why doesn’t anyone care how rough I have it?” And, many of the rest bemoan how bad things are and OMG what if patients touched the electronic version of the sacred manila folder. Drug addicts and disability cheats are going to run rampant! They will probably try to steal medical services! … Odd attitudes to post on a participatory health site.
But I see some rays of hope. It sounds like some people have been working on saner solutions, particularly in the open source realm. And, you know what? You would be amazed at how easily patients could clean up their own records. Heck, we could even put a pink background on their inputs so MDs would know patients fingers were involved instead of those of a surly underpaid, undertrained hospital technician with a bone to pick.
We can even keep the records private. Today, HIPAA pretty much lets anyone with a business relationship with your doctor comb through you files without your knowledge. I would prefer an accountable Google (or equivalent) monitoring and recording all accesses any day.
These are all problems we can fix. All it takes is getting away from the nineteenth century attitudes of the worst MDs and the 1980s attitudes of data processors, er… IT industry experts or whatever they are calling themselves. Let’s see how much of Obama’s medical IT stimulus ends up in the saner world outside of today’s stagnant, self-destructing U.S. health care systems. Let’s hear ideas from anyone who knows how to help get this done
One may define information as answers to set of specific questions; with proper questions data can be converted into information. In the comment by David C. Kibbe, MD MBA, there are some questions; can they span a majority of the answers space required by physicians? I am quite sure it will not be possible to span the entire space, but any set of questions will be better than the situation ePatient Dave so masterfully describes.
Hello Dave,
What can I say. Your story is the best proof that the patient all over the world must start looking at the medical information that is stored on him ASAP and start using PHR’s as well.
I consider it essential to make the paradigm shift to put the ‘patient central’.
Your experience will be broadly shared in the Netherlands. I noticed Lodewijk and Stef already replied so this may help in actual discussions on the topic.
Hi everyone,
First, I want to thank e-Patient Dave for his honesty, integrity, and passion. He is shedding light every day here on e-patients.net, his own blog, and on Twitter.
Second, I want to thank everyone who has commented here and on TheHealthCareBlog.com. Your questions sharpen Dave’s critique and further everyone’s understanding of the issues.
Third, I want to point out that this is not Dave’s “day job” but something he does for free, on his own time, because he wants to make a difference. So if your question doesn’t get answered, ask it again of someone else – or track down an answer elsewhere and bring it back to us.
All those who have benefited from following Dave’s story should go read this post:
A Call for a Patients Speakers Bureau
Patients’ voices make the health care debate come to life, they help us to re-focus on what is at stake, and they provide the “participant-observer” testimony that policymakers need to make good choices.
How can we make this happen?
Another interesting contribution to the discussion of developing better EHRs, especially through an Open Source approach: http://rwjfblogs.typepad.com/pioneer/2009/04/up-on-the-project-healthdesign-blog-lygeia-ricciardi-calls-attention-to-ken-mandl-and-zak-kohanes-perspective-article-in.html
Susannah,
Thanks for bringing up the idea of a patient speaker’s bureau again… Dave did such a great job of articulating it the first time around but bringing it top of mind again is important.
Dave is incredibly generous with his passion and his time. There are others who do the same – have “day jobs” to pay the bills, but have very important input to provide the professionals who are making assumptions, not based on reality to create the healthcare platform of the future.
I’m the other side of the e-patient career coin. I actually committed myself to building a career to empower patients, with a model that says I never take money from patients. I am paid by others who facilitate my work — from About.com to my radio show producers to the newspapers and other outlets that pay me to write for them AND to speak at conferences.
What’s interesting is that early on, some of these conferences paid big bucks to the professional medical people who spoke, but paid me nothing. About a year ago I stopped speaking at those — because I believe I am just as professional as any of them. I’m a professional e-patient. Now I get paid, fairly, what I am due, even though I miss many opportunities because I’m unwilling to speak for free.
But I am an unusual case. Many people with excellent stories and commentary to share, can’t take the time from their day jobs because they don’t get the time off, or don’t have a sponsor to pay their expenses. Those are the Daves of this world. We all need a voice in the “right” places, but without the right vehicles, it just won’t happen.
This is off-topic for this post of Dave’s but it’s also an audience that seems inclined to embrace the idea — so again, I thank you for introducing it. And I wonder if there is an organization out there which would be willing to embrace this idea of a patient speaker’s bureau and run with it? I’m happy to do so – in about two years, when I get my other major projects launched and off my desk. But the time to bite is now.
Dave, I posted the following comment last night, but I don’t see it here. Dunno if I messed up or what:
Dave, the (9:04 EDT) comment you made is very important. Data is useless unless it conveys useful information. It’s easy to extract data from a database. Extracting it in a way to convey useful meaning/information is another story. That’s why database programmers get paid to design decent databases.
I’m too tired to comment much tonight, but I’d like to see a common interface to which EMR’s will export so that we can then import into our PHR’s. It would be a bit of work up front for the EMR software folks, but the one(s) who do(es) that well will be the one(s) who will last in the long run, IMO.
Another thought… diagnosis codes are pretty standard. That’s why they are easy to export to your PHR. Real data…so varied and so…so…well, it’s another story altogether.
MOre later (tomorrow or over the weekend).
Great, great post and wonderful topic.
(Sowens, I hope you’ll post more about the database side of this. I know you know it.)
I have access to my info via my insurer and I looked one day – and I was appalled at the errors. I just hoped the information was used for claims and nothing else. I guess I was naive.
I carry to all my appointments a list of my allergies, my medications (that has how much, when, why and who prescribed it) as well as a list of surgeries (with when and why) that I give every doctor.
I do my best to get a copy of all my medical records (some hospitals are better than others).
It is strange though that the information is so wildly inaccurate. I am wondering though, that one has such a long and complex medical history as I do, that they just cannot keep up. For many years I went undiagnosed and so had many “garbage” codes put in as the doctors did not want to acknowledge what I really had. And now I should look again as I got diagnosed, undiagnosed, and re-diagnosed with the same disease. So someone had to make something up.
Thank you so much for that, Jennifer. As this discussion has continued I’ve been astounded to learn a number of things that I’ll talk about later, but one bears stating now:
Billing codes are entered into the system by clerks, not by anyone who knows your case at a medical level. And as we’ve seen, the system is such a mess (they can’t accurately name your condition) that they often pick anything vaguely related that will get them paid.
And here’s something else that’s done with insurance billing codes: they go into your MIB, a secretive insurance industry database based in Boston that collects data about your medical history, which can be used against you. As this post from last summer shows, with video from Consumer Reports, that info can be used to deny you coverage.
So, me being me, I sent for my MIB record (they don’t make it easy) and the timing was perfect: I discovered a tidbit that was about to expire, making one item untraceable forever.
Before this discussion here I thought the MIB was sleazy, almost scandalous – they collect data about you, they’re not responsible for whether it’s accurate, and it’s hard or impossible for you to protect yourself. The slimy underside of the insurance business.
But now that we know what crap the billing codes are, to me it’s no longer “almost” scandalous, it is a scandal.
Go watch that video and read the post.
My wife also points out, if there are errors in the billing codes, might they be used to declare something a pre-existing condition?
Consider this:
When data is put into a database by someone with one meaning, and taken out by someone with another meaning, disasters can happen.
As Kibbe said, it’s about the information.
The person on the “insert” side of the transaction has one set of information in their hands; the person on the “read” side of the transaction is likely to infer different information, resulting in a total failure of communication.
And it appears we have almost nothing in place to ensure that the inferred information matches the intent.
—- Hey, overseas friends: is this the same where you are or is it uniquely American? And do you have something like the MIB? (See previous comment)
Hi, Dave. Sorting out the problems is part of the equation. Figuring out how to fix them is another. And I think patient input is necessary as one way to go. However, does that mean we need a central database where everything is filtered so the patient will always have access and thus everyone accessing this patient’s records must also see patient input?
The MIB is clearly an abomination. In a country with nationalized health care where there is no risk of losing insurance, an involuntary MIB-like entity might be justified and is likely to be under strong political and regulatory control.
In the US system, where your private _information_ (never mind the data) can and will be used against you, many patients will choose PHRs where they have the absolute right to control the contents.
Given a choice between a PHR where patients can only annotate the errors and one where they have the power to delete any data they choose, how many will accept the annotation only option?
And this brings us to what I increasingly think is a core question: Whose data is it, anyway?
Above I mentioned our post last June about Doc Searls’s story. I just looked at that post and found this quote from Doc’s own post, which I’m now seeing as profound:
And as often happens in closed systems (with no transparency), it appears the resulting systems are unreliable.
Well, here’s a corker: there’s a discussion on The Health Care Blog, Whose data is it, anyway? In it, a guy who signs himself “MD as HELL” says: “The doctor’s work is proprietary, the intellectual property of the doctor.”
I may be misconstruing his/her intent but I think s/he is espousing the views of Medical Justice, which we dealt with last month. Good luck with that!
Otoh, s/he does raise a good point about whether the individual can be counted on for good judgment in saying what they do or don’t have.
Methinks this is a non-trivial subject, and a great one. For participatory medicine to work, there needs to be a collaborative partnership – and that doesn’t work any better with an un-candid pt than with an un-open doc.
I sense a Bill of Rights & Responsibilities coming on.
“Whose data is it anyway?”
We are just having this discussion on the cushings-help message boards. We are trying to help someone obtain a medical record her doctor refuses to give her unless she comes in for a paid visit. She is in Oregon. This document, on page 8, says:
Who owns my medical record?
Under Oregon law, your health care provider owns the actual medical record. But you have the right to see and get a copy of it.
On down the page, it also says, “Your right to amend this information may be limited, though.”
This may vary by state. Georgetown University has some great resources: Center on Medical Record Rights and Privacy: State Guides.
Great post Dave, and I look forward to hear more about this (and to continue these discussions) at the Medicine 2.0 congress (Sept 17-18, 2009, Toronto).
Medicine 2.0 is all about patient participation, and we are happy and proud to have you (Dave) as one of the keynote speakers at Medicine 2.0 in 2009, alongside with many other excellent speakers in the field (as an aside, Dave is the only invited speaker, all health professionals, researchers and entrepreneurs pay for travel and registration fee themselves).
(btw – a patient speakers bureau is a great idea, but I think it is the responsibility of conference organizers to set aside funds for patient participation).
The Society of Participatory Medicine is another good idea. As to the Journal of Participatory Medicine, I am not convinced the world needs yet another journal – the Journal of Medical Internet Research (JMIR) is more than happy to publish this kind of work at the intersection of ehealth and participatory medicine – and has been doing this since over 10 years.
Here’s another disturbing (to me) look at unintended consequences of this insurance billing folly: I just noticed a discussion last month on the Wall Street Journal health blog about Do Docs & Nurses Really Want Pts to Speak Up? The first commenter, Basora, says s/he found out the hard way that if s/he brought up additional topics during a fixed-length visit, an additional billing code would get added. This didn’t cause a problem when the insurance covered everything but was quite a problem with a high-deductible policy. Afterthought added Sunday: actually, it might not have caused a *personal* cash problem, but it inflated the total cost to the system. It’s a myth to say “It didn’t cost anything – insurance paid for it.”
Another commenter said something I heartily believe: “if you find a general practitioner/internist whom you trust, don’t let him/her get away…hang on for dear life.” :–)