This is a complex post, so don’t jump to any conclusions.
Two weeks ago (gad, was it that long?) I asked you to think about something for a few days:
Imagine that for all your life, and your parents’ lives, your money had been managed by other people who had extensive training and licensing. Imagine that all your records were in their possession, and you could occasionally see parts of them, but you just figured the pros had it under control.
Imagine that you knew you weren’t a financial planner but you wanted to take as much responsibility as you could – to participate. Imagine that some money managers (not all, but many) attacked people who wanted to make their own decisions, saying “Who’s the financial planner here?”
Then imagine that one day you were allowed to see the records, and you found out there were a whole lot of errors, and the people carefully guarding your data were not as on top of things as everyone thought.
Two weeks before that post, I’d had a personal breakthough in my thinking. For a year I’d been a rabid enemy of Google Health, but now I said: I’m putting my data in Google and HealthVault: “I’m concluding that we can do more good by aggregating our data into large, anonymized databanks that smart software can analyze to look for patterns. Early detection means early intervention means fewer crises.” And I observed that the power of Web 2.0 “mash-ups” …
…lets people create software gadgets without knowing how they’ll be used, it lets people build tools that use data without knowing where the data will come from, and it lets people build big new systems just by assembling them out of “software Legos.”
So, I said, “I’m in.” I decided to punch the big red button and copy my personal health data into Google Health. What happened is the result of PatientSite’s “version 1” implementation, not their eventual full implementation, of the interface. To my knowledge, zero or one other hospitals have any interface at all, and as I’ll say later, I’m not even sure how much of the Google Health side of the connection is complete. Nonetheless, what I learned about my own data was quite informative, and quite surprising. (I’ve discussed what follows with hospital staff; this isn’t gossip behind anyone’s back. IMO, empowered people don’t gossip, they communicate clearly and directly with the people involved.)
When Google Health launched last May, my hospital’s CIO blog said “we have enhanced our hospital and ambulatory systems such that a patient, with their consent and control, can upload their BIDMC records to Google Health in a few keystrokes. There is no need to manually enter this health data into Google’s personal health record, unlike earlier PHRs from Dr. Koop, HealthCentral and Revolution Health.” So I went into my patient portal, PatientSite, and clicked the button to do it. I checked the boxes for all the options and clicked Upload. It was pretty quick.
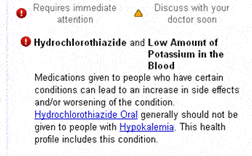
 But WTF? An alarm: “! Requires immediate attention” [see screen capture at right]
But WTF? An alarm: “! Requires immediate attention” [see screen capture at right]
Okay, yes, HCTz is my blood pressure medication. But low potassium? That was true when I was hospitalized two years ago, not now. What’s going on?
Then I saw the list of “conditions” it told Google I have. At left is a partial screen grab, and at right is the complete condition list that PatientSite transmitted: (Spoiler alert; this stuff is biological and might seem gross.)

Acidosis Anxiety Disorder Aortic Aneurysm Arthroplasty - Hip, Total Replacemt Bone Disease CANCER Cancer Metastasis to Bone Cardiac Impairment CHEST MASS Chronic Lung Disease Depressed Mood DEPRESSION Diarrhea Elevated Blood Pressure Hair Follicle Inflammation w Abscess in Sweat Gland Areas HEALTH MAINTENANCE HYDRADENITIS HYPERTENSION Inflammation of the Large Intestine Intestinal Parasitic Infection Kidney Problems Causing a Decreased Amount of Urine to be Passed Lightheaded Low Amount of Calcium in the Blood Low Amount of Potassium in the Blood Malignant Neoplastic Disease Migraine Headache MIGRAINES Nausea and Vomiting Nephrosis PSYCH Rash Spread of Cancer to Brain or Spinal Cord Swollen Lymph Nodes
Yes, ladies and germs, it transmitted everything I’ve ever had. With almost no dates attached. (It did have the correct date for my very first visit, and for Chest Mass, the x-ray that first found the undiagnosed lesion that turned out to be cancer. But the date for CANCER itself, the big one, was 5/25/07 – four months after the diagnosis. And no other line item had any date. For instance, the “anxiety” diagnosis was when I was puking my guts out during my cancer treatment. I got medicated for that, justified by the intelligent observation (diagnosis) that I was anxious. But you wouldn’t know that from looking at this.)
See how some of the listed conditions have links for More Info?  Let’s see, I was diagnosed with optical migraine. (I diagnosed myself, actually, by researching my symptoms and finding this illustrated site. That’s what e-patients do; it saves time in the doctor’s office… I brought a printout, with a dated list of episodes.) But optical migraine is not the impression you’d get from reading my Conditions list – in fact during my cancer workup one resident said “But you have headaches, right?” “No,” I said – “optical migraines, but without pain.” (Update 4/2: the illustration at left shows the dazzling pattern that an optical migraine produces.) So for that item in the conditions list, I clicked More Info. I didn’t get more info (i.e. accurate info) about my diagnosis, just Google’s encyclopedia-style article about migraines in general. (An optical migraine has little in common with migraines in general.)
Let’s see, I was diagnosed with optical migraine. (I diagnosed myself, actually, by researching my symptoms and finding this illustrated site. That’s what e-patients do; it saves time in the doctor’s office… I brought a printout, with a dated list of episodes.) But optical migraine is not the impression you’d get from reading my Conditions list – in fact during my cancer workup one resident said “But you have headaches, right?” “No,” I said – “optical migraines, but without pain.” (Update 4/2: the illustration at left shows the dazzling pattern that an optical migraine produces.) So for that item in the conditions list, I clicked More Info. I didn’t get more info (i.e. accurate info) about my diagnosis, just Google’s encyclopedia-style article about migraines in general. (An optical migraine has little in common with migraines in general.)
The really fun stuff, though, is that some of the conditions transmitted are things I’ve never had: aortic aneurysm and mets to the brain or spine. So what the heck??
I’ve been discussing this with the docs in the back room here, and they quickly figured out what was going on before I confirmed it: the system transmitted insurance billing codes to Google Health, not doctors’ diagnoses. And as those in the know are well aware, in our system today, insurance billing codes bear no resemblance to reality. (I don’t want to get into the whole thing right now, but basically if a doc needs to bill insurance for something and the list of billing codes doesn’t happen to include exactly what your condition is, they cram it into something else so the stupid system will accept it.) (And, btw, everyone in the business is apparently accustomed to the system being stupid, so it’s no surprise that nobody can tell whether things are making any sense: nobody counts on the data to be meaningful in the first place.)
It was around this time that I commented on Ted Eytan’s blog, “when you’re exporting to a new system, the rule is, Garbage Out, Garbage In. (Hint: visibility into the data in your old system may leave you aghast.)” We could (and will someday) have a nice big discussion about why the hell the most expensive healthcare system in the world (America’s) STILL doesn’t have an accurate data model, but that’s not my point. We’ll get to that.
And now we get to why I said, at the outset, don’t jump to conclusions. I’m mildly bitching about PatientSite, but that alone wouldn’t justify staying up to 3 in the morning all night writing a 2800 3500 word post; that one system isn’t a big deal for e-patients everywhere. (And besides, although PatientSite is old and clunky, a 1999 system if I ever saw one, it beats what most hospitals offer, and it did the job very well for me during my illness. And this is just version 1 of the interface; the current folly is not a permanent situation.)
The BIG question is, do you know what’s in your medical record? And THAT is a question worth answering. For every one of you.
See, every time I speak at a conference I point out that my 12/6/2003 x-ray identified me as a 53 year old woman. I admit I have the man-boob thing going on, but not THAT much. And here’s the next thing: it took me months to get that error corrected, because nobody’s in the habit of actually fixing errors. Think about THAT.
I mean, some EMR pontificators are saying “Online data in the hospital won’t do any good at the scene of a car crash.” Well, GOOD: you think I’d want the EMTs to think I have an aneurysm, anxiety, migraines and brain mets?? Yet if I hadn’t punched that button, I never would have known my data in the system was erroneous.
And this isn’t just academic: remember the Minnesota kidney cancer tragedy just a year ago, which arose at least partly out of an error that ended up in the hospital’s EMR system. Their patient portal allowed patients and family to view some radiology reports, but not the one that contained the fateful error.
The punch line came when I got over my surprise about what had been transmitted, and realized what had not: my history. Weight, BP, and lab data were all still in PatientSite, and not in Google Health. So I went back and looked at the boxes I’d checked for what data to send, and son of a gun, there were only three boxes: diagnoses, medications, and allergies. Nothing about lab data, nothing about vital signs.(So much for “no need to manually enter this health data into Google’s personal health record.”) And of the three things it did transmit:
- what they transmitted for diagnoses was actually billing codes
- the one item of medication data they sent was correct, but it was only my current BP med. (Which, btw, Google Health said had an urgent conflict with my two-years-ago potassium condition, which had been sent without a date). It sent no medication history, not even the fact that I’d had four weeks of high dosage Interleukin-2, which just MIGHT be useful to have in my personal health record, eh?
- the allergies data did NOT include the one thing I must not ever, ever violate: no steroids ever again (e.g. cortisone) (they suppress the immune system), because it’ll interfere with the immune treatment that saved my life and is still active within me. (I am well, but my type of cancer normally recurs.)
In other words, the data that arrived in Google Health was essentially unusable.
And now I’m seeing why, on every visit, they make me re-state all my current medications and allergies: maybe they know the data in their system might not be reliable.
Hey wait, a new article in the Archives of Internal Medicine (co-authored by our own Danny Sands, my very own primary) says Clinicians override most medication alerts. Could it be they’ve been through this exercise themselves, and they consider the data unreliable? (Or do they just not trust computers?) (Hey Pew Internet, wanna check for generational differences?) Who knows, perhaps the resident in the migraine story has learned early on that the data in his system is not to be taken at face value – I don’t know.
In any case, my hospital is very proactive and empowering to staff about root cause analysis for failures, with its “SPIRIT” program, and they’ll add any process or form that can catch potential errors. That’s good. But wait: On numerous visits, I’ve restated on those forms “no steroids.” But evidently what I write on the forms never gets entered into the system. Hm.
I work with data in my day job. (I do marketing analytics for a software company. We import and export data all the time.) I understand what it takes to make sure you’ve got clean data, and make sure the data models line up on both sides of a transfer. I know what it’s like to look at a transfer gone bad, and hunt down where the errors arose, so they don’t happen again. And I’m fairly good at sniffing out how something went wobbly.
And you know what I suspect? I suspect processes for data integrity in healthcare are largely absent, by ordinary business standards. I suspect there are few, if any, processes in place to prevent wrong data from entering the system, or tracking down the cause when things do go awry.
And here’s the real kicker: my hospital is one of the more advanced in the US in the use of electronic medical records. So I suspect that most healthcare institutions don’t even know what it means to have processes in place to ensure that data doesn’t get screwed up in the system, or if it does, to trace how it happened. Consider the article in Fast Company last fall, about an innovative program at Geisinger. Anecdotally, it ended with this chiller:
“… a list of everybody that accessed the medical record from the time he was seen in the clinic to two weeks post-op.’There were 113 people listed — and every one had an appropriate reason to be in that chart. It shocked all of us. We all knew this was a team sport, but to recognize it was that big a team, every one of whom is empowered to screw it up — that makes me toss and turn in my sleep.”
In my day job, our sales and marketing system (Salesforce.com) has very granular authorizations for who can change what, and we can switch on a feature (at no extra cost) to track every change that’s made on any data field. Why? Because in some business situations it’s important to know where errors arose – an error might cause business damage, or an employee might sue over a missed quota.
So I’m thinking, why on earth don’t medical records systems have these protections? If a popular-priced sales management system has audit traces, to prevent an occasional lawsuit over a sales rep’s missed commission, why isn’t this a standard feature in high-priced medical records systems? In any case, in the several weeks since these discoveries started, as far as I know they haven’t figured out how my wrong data got in there. And without knowing how the wrong data got in, there’s not a prayer of identifying what process failed.
BUT AS I SAID, this is not about my hospital; a problem at my hospital affects only one scrillionth of patients in the US, not to mention the rest of the world. And please don’t blame my hospital’s CIO; I think what he wrote about the Google Health interface was overzealous, but I believe he’s a good man, committed to helping us own our own data (his work on the Google Health advisory board was unpaid), and this post isn’t about him: as far as I know, this hospital is farther along than anyone else: hardly anyone else has implemented a Google Health interface. (Perhaps for good reason.) Nor is this a slam on Google Health.I haven’t probed yet into whether there are limitations in what it does; might be fine, might not. Heck, neither PatientSite nor I have put any good data into it yet. (And I haven’t even touched HealthVault.) None of that is my point. Rather, my point is about the data that was already in my PHR, uninspected. For that, let’s return to my previous post:
Then imagine that one day you were allowed to see the records, and you found out there were a whole lot of errors, and the people carefully guarding your data were not as on top of things as everyone thought.
In my day job, when we discover that a data set has not been well managed, we have to make a decision: do we go back and clean up the data (which takes time and money), or do we decide to just start “living clean” from now on? My point, my advice to e-patients, is:
- Find out what’s in your medical record. What’s in your wallet, medically speaking? Better find out, and correct what’s wrong.
- Get started, manually, moving your data into Google Health, HealthVault, or some such system. I’ve heard there are similar PHR systems (personal health records), not free but modestly priced, that can reportedly make this easier. I’m sure their friends will show up here in the comments. (Feel free to post product info links in the comments, everyone.)
- Let’s start working, now, on a reliable interoperable data model. I know the policy wonks are going to scream “Not possible!” and I know there are lots of good reasons why it’s impossibly complex. But y’know what else? I’ve talked to enough e-patients to be confident that we patients want working, interoperable data. And if you-all in the vendor community can’t work it out, we will start growing one. It won’t be as sophisticated as yours, but as with all disruptive technologies, it will be what we want.And we’ll add features to ours, faster than you can hold meetings to discuss us.I have to say, while researching this post I was quite surprised at how very, very far the industry has to go before reaching a viable universal data model. New standards are in development, but I’m certain that it will take years and years and gazillions of dollars before any of that is a reality. (What, like costs aren’t high enough already?) In the meantime, your data is probably not going to flow very easily from system to system. Far, far harder than (for instance) downloading your data to Quicken from different credit card companies and banks. (Wizards and geeks refer to this “flow” issue as “data liquidity.” We’ll talk about that in the future.)
- Let’s start working, now, on an open source EMR/PHR system. The open source community creates functionality faster, and more bug-free, than commercial vendors do – and nobody can latch onto proprietary data in such systems to milk more margin out of us… because it ain’t proprietary.The great limitation of open source is that it’s generally not well funded. But you know what? Every person in America (including software engineers) is motivated to have good reliable healthcare systems, and I assert that the industry ain’t getting’ it done on their own. As I said in my Thousand Points of Pain post (cross-posted on IBM’s Smarter Planet blog as A business thinker asks, what will it take to get traction?), it’s fine with me if industry vendors come along too – but I would not stake my life on their moving fast enough for my needs. Or your mother’s needs.
Want a case study with real consequences? Recall what happened last year to famed Linux guru Doc Searls when he couldn’t read his own scan data, because good cross-platform image viewing tools weren’t available. (His prescription: the patient should be the platform and “the point of integration.”) Well, okay, so Doc was a year ahead of me. I’m catching on. This illustrates why I think people from outside the profession may be our greatest asset in building what patients really need: patients tend to build what they want. And we who work with data all day know that these problems are not unsolvable.
My bottom line: I think we ought to get our data into secure online systems, and we shouldn’t expect it to happen with the push of a button. It’ll take work. So let’s get to work. You know the work will be good for you, and heaven only knows what you’ll learn in the process. You’ll certainly end up more aware of your health data than when you started. And that’s a good thing.
Minor edits made 4/12/2009, and 1/5/2012 and 9/19/2022 for clarity and to adjust to this blog’s new format




Dave: A superb discussion. I am reposting my reply to a query on the health care blog as to “who’s data is it anyway”?
>>>>>>
MD as Hell Writes “The doctor’s work is proprietary… the intellectual property of the doctor.”
An interesting POV; yet IMJ it couldn’t be further off the mark. The Wisconsin law referenced by Dr. Dan Johnson gets closest to the issue’s correct nature and granularity.
I will take Wisconsin’s statutory wisdom one step further: the patient is the sole principal/owner of all “intellectual property” (IP) which by necessity includes all tissue, fluids, and related health information; whether clinical, administrative or legal. The IP is then situationally and proactively “leased” or “licensed” to the provider during the care process.
All providers, whether physicians, allied health practitioners, or institutional health care entities, systems or parents, are agents who bear the “duty of care” with respect to the proper handling of the patient’s (or member’s) intellectual property.
Whether the “bucket” for the repository of health information is a flash drive or cloud based solution (MS HealthVault or Google Health), for me resides on the cloud side, authentication or privacy challenges to date notwithstanding. The cloud solutions are inevitable, IMJ.
So my take on the question originally posed, is it’s the patient’s and/or member’s data; though an argument can be made for provider co-ownership during active episodes of care, or other relevant intervals.
See post on subject here:http://2healthguru.wordpress.com/2009/03/26/i-will-license-or-lease-my-health-information-to-providers/
The one thing that occurs to me from the discussions above that is at the origin of the problems that Dave (and sadly with him many others) encounter, is that electronic record systems primarily where developed as “electronic billing systems”. Its main purpose is to make sure that the money is coming in. The registration of health related data for medical use is a ‘by-product’. This is why relevant medical data turned into ‘garbage’.
As David Kibbe and others nicely demonstrated everybody in the health care system knows this and therefore don’t use and/or rely on health data provided by others. As a result doctors ask and/or test for the same things over and over again, just to be sure that they’ve got it right for their own part. This seems to be a practical solution (for lack of something better) but has devastating effects on our healthcare system. Patients get suboptimal or outright wrong care. Due to the lack of communication people stick with the one healthcare provider they trust. It’s difficult to go to other healthcare providers, because it would be impossible to provide a proper overview of ones medical history (could it be that many doctors embrace the ‘garbage’ because it creates a perfect vendor lock in?). As a result (and this has been shown elegantly in the comments above) people just don’t trust the healthcare system anymore. On top of that valuable resources are being waisted by doing the same thing over and over again.
To solve this we need to start to create new ‘participatory health information systems’ in which participation in combination with information systems based on open standards leading to citizen/patient centric ‘health information’. The PHR should be an essential part of such an integrated health record that primary purpose is the support of continuing, efficient and quality integrated health care and it contains information that is retrospective, concurrent and prospective. (ISO/DTR 20514).
Although I’m aware that many discussion about IP/ ownership of data will follow and a lot of hurdles have to be taken, my firm opinion is that we, the citizen/client/ patient should be the caretaker of our own health record and have the primary control to determine who can seen what and when
As somebody once simply put it to me: if you bring your car to the garage, who’s the owner of the cars service booklet and would you agree if the care repair person wrote down garbage which can only used/ deciphered by himself?
Stef Verlinden
To Stef’s point, this is getting the attention of the FDA. In a keynote at HIMSS yesterday, Brian Fitzgerald of the FDA pointed to the ISO 80001 standard. See http://www.24x7mag.com/issues/articles/2008-07_07.asp for a rather technical description.
Greg’s response sent me to a trail full of very interesting conversations. It makes our future even more complicated than it already was. A doctor wrote judiciously
We should make sure we do not become another prime examples of the law of unintented consequences, by removing entirely the privacy the doctors require to be able to put the data in their context. The doctors need their space too!
And if all the comments made by doctors become part of the PHR/EHR what will stop the MIB from grabbing it and using them against you. Would anyone want to have insurance claims denied because in a private comment, a doctor writes about a suspected substance abuse? MIB is
In other words currently sharing of your health data is protected by financial regulators!
As Dave wrote earlier I sense a Health Data Bill of Rights & Responsibilities coming on.
And don’t forget, healthcare reform is too important to be left in the hands of professionals who live out of this guargantuan 17% of GDP.
Gunther,
in response to your last paragraph, i.e the Journal of Participatory Medicine, I understand why you may feel this way.
As a co-author of an article published in JMIR, How Cancer Survivors Provide Support on Cancer-Related Internet Mailing Lists, I have great respect for your publication, which you pioneered in 1999, when very few understood the need to publish science about the medical use of the Internet. I also know the limitations you have in place to guarantee that only the most rigourously scientific papers get published. It is great in many ways and has its niche as we will have ours.
I hope you will embrace what we are trying to do, mixing science from academic settings with stories from the trenches to demonstrate the transformative power of patients’ and caregivers’ active involvement in all aspects of medical care. Besides providing evidence and narratives in a variety of formats, JPM will offer guidance to thought leaders from all sides of the equation – health care professionals, academics, patient advocates, payers, and employers – on how to implement this paradigm shift in their particular settings.
To approach this massive challenge, JPM will be participatory at every level. From its inception there will be two co-editors-in-chief, one representing the patient side and the other obviously representing medical professionals. Our amazing Board of Editors will be composed of experts with varied expertise, going far beyond medicine. Further, we’ll diverge from your model by focusing on every aspect of participatory medicine, going beyond the internet as a tool of empowerment.
We are living in a big world. There is room for many facets of knowledge. Hopefully we’ll be a nice addition.
I encourage people to read the short post that Gregg Masters linked to, titled “I will license or lease my health data to my providers.” I’m not saying I endorse the idea but it’s provocative in a good way: thought-provoking.
At a deep and possibly disturbing level it gets to the bottom of the most profound issue: who IS responsible for my health? If I want to control what information my providers see, who’s responsible for any resulting problems?
In my case I love and trust my docs. (Their computers, not so much.:–)) So my choice would be to use the data they collect.
But you can bet, from this moment forward I want to INSPECT any data after it gets transferred to another system!
Fair enough, Gilles, I wish you good luck with this. Creating a new journal from the scratch is not a small undertaking, but if you have no ambitions regarding peer-review and getting Medline indexed, then this is perhaps easier.
I don’t want to respond in detail, as this is probably a separate thread/blog post, but just for the record:
1. JMIR’s editorial board is wide open, and in fact we are actively seeking consumer/patient involvement. See http://www.jmir.org/about/editorialPolicies#custom2
2. We do not discriminate against submissions from patients/consumers (you cited your own paper). In fact, I’d hope that Dave would submit his experiences above (and perhaps a summary of the reactions) as a letter/article to JMIR (APF waived).
3. JMIR is in principle open for submissions which do not deal with Internet or eHealth – we call ourselves “the leading open access peer-reviewed transdisciplinary journal on health and health care in the Internet age.”.
What I offered was to create a section on participatory medicine within JMIR, with the section editor(s) having editorial control over that section.
I can understand your position and – either way – support the creation of a separate journal as well, but I guess the true reason for lack of collaboration is branding – which is a fair reason.
Yes, gents, let’s take this discussion elsewhere – we don’t want to get known as a drifty blog. Good conversation, just not here. :)
btw, Jennifer, if you wouldn’t mind posting something specific about the errors you saw, it might help people be clear about this.
For instance, since the original post, I learned that during a pre-cancer-treatment cardiac stress exam of some sort, a doctor noted a very slight enlargement at the base of the aorta. This was really really important to put in the records because the treatment I got can have severe cardiac effects, even death. BUT, then some insurance clerk saw that and inserted a billing code for aortic aneurysm.
So, you tell me: did the patient have an “aortic aneurysm” or not?
Very informative. And information is empowering, because it lets us have some sense of what the hell is going on. Which is always the first step to having power in the matter.
I went back and now my insurance company does not keep the information – but the reported information just in shows one doctor reported “myasthenia gravis” and another reported “general malaise” (what the heck is that?). There is nothing about all my endocrine disorders save one mention that really keep me down. I guess I need to order my MIB too! Thanks!
Re code errors, when I was at a lab recently, the tech could not read the docs writing and so just put in whatever she thought and instead of being panhypopituitary, I was something like a kidney disorder. She did not take well to being corrected but it was either going to be billing or my record that was going to be wrong. I guess she had no idea what my tests were about either. I got her to correct them finally.
Wow, this is really great, thoughtful stuff, Dave. Importing data can always be tricky, but it’s so tempting to just click the button and hope for the best. Patient access to — and control of — health records is key to better outcomes, so it’s great to see you leading the way toward that. I hope you do try HealthVault – we’ve got to push the health care system if we want to see change happen soon!
Hi Rob – anything in particular lead you to suggest HealthVault? You affiliated with anyone in particular? (I don’t mind, just like to get to know people.)
I want to emphasize again that nothing I did reflects in any way on Google Health.
Now that I think of it, hey, I oughta punch that other button in PatientSite, “upload to HealthVault,” and see if anything different happens. But not tonight – I got work in the morning. :–)
Wouldn’t a PHR answer the “five questions”? Who, what, when, where and why?
Timestamp, geocode, observer, observed, observation.
“Observation” may be semantically rich but wouldn’t taxonomy, concept, value be a start?
Is it all that hard?
Jim, the PHR database side isn’t the hard part. It’s extracting data from the EMR side that’s so tough. Take into account there are umpteen dozen EMR’s all with various datatypes and repositories. Add in HIPAA, security issues, and interface that is user-friendly, and it’s a fairly big ball of wax.
Instead of two interfacing systems, why not ONE PHR where P stands for PARTICIPATORY instead of PERSONAL. Then, import/export becomes less troublesome, overall security is easier, the patient has access to all her informtation/data, and it all stays in one spot. OR, define some standards so that data is interchangeable among EMRs/PHRs.
Too tired to write more…hope I made enough sense.
Ok… a “P.S.” of sorts: So many databases, (especially the older, clunky models in place in many places) are not relational. Thus they are redundant. Information can be very conflicting and if changed in one place may not be in another. I imagine most of us have experienced that when dealing with medical systems as patients.
Thanks. I agree the EMR side is a problem and there is no sane solution.
Portable solutions such as USB sticks constrain the choice of technology. I can not imagine people carrying around a relational database. I can imagine carrying around XML+CSS.
Why not stuff your history in Google Health? The web interface is inadequate and apparently imports are poor. CCR does provide for time stamps, the observer, the observer’s role. Maybe uploading with the API would overcome the limitations of the web interface.
Sharing with providers appears clunky. USB sticks and Windows autorun would discourage providers from putting your USB stick in their computer.
Obviously, I am wading in the swamp. This site is the most encouraging thing I have found.
Hehe….laughed on “carrying around a relational database”.
Actually, depends on the database…doesn’t have to be clunky. Data is what is clunky, depending on format. But I’m thinking the answer is an interface anyone can use with a central data site, built on standards that make data easily imported/exported. It’s doable. And should be the long term goal. Any EMR should really be a PHR (P=Participatory)and accessible by provider and patient, as well as modifiable by both.
This whole thing has led me to try, with some trepidation, dipping my toe into the world of medical data formats and the Google Health API. For those who aren’t afraid of a little XML, try this: the Developer Best Practices page for Google Health, which lists the various data formats Google can accept for different things:
1. Medications: RxNorm, NDC, FDB
2. Conditions and symptoms: SNOMEDCT, ICD9, FDB
3. Procedures: CPT, SNOMEDCT
4. Allergies: SNOMEDCT
5. Immunizations: CPT
6. Lab test: LOINC, CPT, SNOMED
For conditions, PatientSite transmits ICD9, which is billing data. I don’t know what it transmits for medications; for allergies I presume it’s SNOMEDCT.
As much as I’m not a serious data geek, I know first-hand that XML is understandable and human-readable. So what the heck, maybe we-all can actually stick in our fingers and SEE what the geeks are doing, and express ourselves … with the counsel of real geeks like Robin. :–)
Oh, and the docs. Yeah, participating with the docs is a good idea. :–)
Dave –
I am involved in getting people to take a look at – and, I hope, sign up for – HealthVault, though I don’t work directly for the MS team.
I really liked your piece, and it’s provoked me to ask for insight from the MS people about importing data – it does seem that there should be more to it than just clicking “import,” but not so much that you’ve got to re-enter all your data by hand, which is both time-consuming and a potential source of errors. Once I hear back, I’ll let you know what they say.
And yes, absolutely, this issue seems to have a lot more to do with your provider’s system than Google Health.
“patients are getting sicker and dying from faulty records today.”
That is true. It is also true that you can have your own records and no one cares. I had stacks of lab tests showing positive for Cushing’s Disease for years. I can name 27 doctors in the state of Ohio and beyond who either never read them, would not read them, did not care what they read, or laughed at us while reading them.
I have built three pieces of medical software. Two of them had to do with billing, review, preauth, and a few other pieces. The first one dealt with pretty much everything. From the office, to the hospital, to the drugstore and many stops in between. I am intimately familiar with the data models. There are standards to follow in some cases. For example, how to transmit data.
I have also, as mentioned, been on the other end as a patient. I have no access to my digital records. That is another story.
The more important issue is that the doctors and nurses fail to listen to the patient. Most of the times we have gotten doctors notes on my case to go to the next specialists, they were wrong. Not some wrong, but a lot wrong.
My daughter, who has the same type of tumor I had, has the same problem. You can talk to the doctor but they have already made up their minds and the wrong information is getting put down. If they can’t do it right on paper, they certainly will not get it right digitally. Garbage in = Garbage out.
This goes way beyond digital records or rather I should say the problem existed way before digital records. It goes way deeper than billing codes and no piece of software or data model can fix that.
The existence of accurate medical records has to start with the men and women in the medical field. When doctors are arrogant and have god complexes no one wins. Neither does the patient with 75 medical tests confirming Cushing’s who goes from a hospital in Dayton, Ohio to Cleveland Clinic just to be told that those records do not matter and he will have to be re diagnosed. Is places like Cleveland Clinic shunning those records because they believe (or know) that medical records are full or errors? I used to think it was just arrogant doctors. After this article, I wonder if it is that they simply know about the bad record keeping in the medical field.
SOwens,
My heart goes out to you. I’m glad to have you in this discussion, with your knowledge of data technology. Please stick around and participate.
And speaking of participating, it sounds like the doctors you interacted with were worst-case examples of doctors who won’t listen. That’s a big aspect of what the Society for Participatory Medicine will be about: establishing the validity of and need for patient/professional collaboration, and documenting principles and practices for how to do it effectively.
Some of us, like me, have had doctors who need no training on this. (Well, most of my docs anyway.) But part of our work will be education and training of healthcare professionals.
The White Paper at the top of this site contains numerous stories like yours. It also has inspiring stories of great contributions e-patients made, which saved the day. It’s our intention that in years to come there will me more of the latter and fewer of the former.
<Soapbox>
IMO two fundamental aspects are an improved norm for the pt/professional relationship and improved patient ability to control their own destiny, including being responsible for their own data. That’s where this thread fits in: as in any liberation movement, we need to become educated about the things that used to be done for us. And we can.
</Soapbox>
@ Jim Tarvid: Timestamp, geocode, observer, observed, observation are indeed the essential requirements.
‘We’ have differentiated observation a bit further:
– Observation: information created by an act of observation, measurement, questioning, or testing of the patient or related substance (tissue, urine etc), including by the patient himself (e.g. taking own blood glucose measurement), in short, the entire stream of information captured by the investigator, used to characterise the patient system;
-Instruction: an action is to be carried out in the future and the timing of that instruction.
– Action: a record of intervention actions that have occurred, due to instructions or otherwise;
– evaluation:thoughts of the investigator about what the observations mean, and what to do about them, created during the evaluation activity, including all diagnoses, assessments, speculative plans, goals;
Such an differentiation is necessary in order to be able to discriminate between, for instance a bloodpressure measurement that took place (an observation), the instruction to perform a blood pressure measurement and the evaluation of the values obtained during such a measurement.
http://www.openehr.org/134-OE.html?branch=1&language=1
Just my 5 cents.
Stef
The Google Health GUI allows editing entries and adding timestamps. Looking into the API to see how one might download, update and upload information.
AAFP has XSL templates to render CCR XML data (Google supports a subset of CCR). Haven’t found a suitable editor yet.
Stef’s suggestion on observations makes sense. Haven’t dug through the EHR Information Model enough to see how it would relate to CCR.
From a patient POV, I would want to have a copy of my information in my possession and in my hands. Many of my providers are not prepared to view my records on Google Health. Paper would help.
Google Health is far from complete (images, diet and exercise being notable). I would like to be able to complement the history.
I fear I am avoiding HealthVault at some peril and will probably give it a few hours in the not too distant future.
Service providers can make data available for import to Google Health but are responsible for the local store. Several thousand large XML files are better than several thousand manila folders. MySQL and Pentaho would serve my urges as a data miner.
Stef – do you have any code to look at?
Jim: as far as (I think to) understand it right now CCR defines a minimal data set which is required to guarantee the ‘continuity of care’. This is essential and a very good starting point. Unfortunately this says nothing about the quality/ integrity/ etc. of the data in the underlying information systems. So altough the correct data set might be exchanged, it doesn’t solve the garbage out/in issue.
To slove that issue one needs to start with open standard based information systems, which prevent the garbage collection and instead produces valuable nformation that an be re-used for the lenght of time (maybe not that long but at least for a good amount of decades:-) ). That is the aim of openEHR.
Once your information is collected and stored properly with all the checks and balance it’s a piece of cake to produce a CCR data set that can be exchanged with other (also non openEHR systems). There are quite a few people wihtin the community who want to do this, but so far we didn’nt have an ‘urgent’ use case. I’m sure that if we come up with such an ‘urgent’ use case, the community will be more than willing to create a CCR demonstrator.
As for your question for the source code: I’m not a technical person so I don’t know exactly which code you want to see. For instance here;
http://www.openehr.org/projects/java.html
you can find the source code of the Java kernel, but there is also a .net and a Python kernel that you can view/download.
CCR goes further in the direction of maintaining data integrity than many realize. The CCR standard includes a Source attribution field for every data object (e.g. a medication, a vaccination, a lab result) and allows for that object to be signed by the author. This gives a large incentive for data exporters to keep things accurate and reduces their liability if they preserve original signatures and attribution as they assemble a useful clinical summary such as the CCR.
This concept of individually signed objects may sound far-fetched but it’s what patients had when prescriptions, vaccination forms and labs were on paper. The rush to e-prescribing and opaque EMR has taken a lot of transparency out of the system.
‘The CCR standard includes a Source attribution field for every data object ‘.
Great, that’s really a good start. I also like the concept of individually signed objects.
‘and allows for that object to be signed by the author’
but why isn’t this signature mandatory. I seriously doubt whether ‘reduction of their liability’ is a large enough incentive for health care providers to clean up their garbage. ‘If it’s not signed who can prove that I produced this garbage or even sended it’.
From a citizen/patient perspective I would strongly advocate to make this signature mandatory since that would provide this incentive. If it’s digitally signed the signer is undoubtly responsible for the content.
HL7 and the CDC use OID – http://en.wikipedia.org/wiki/Object_identifier
Why not sign the object – http://en.wikipedia.org/wiki/Public_key_infrastructure
Log the IP address of device that records the initial entry.
Geocode the point of entry and the point of service delivery – http://en.wikipedia.org/wiki/Geocode
Disk storage is cheap. Data integrity invaluable.
FWIW – a Resource Bundle Editor is available for both Eclipse and Netbeans.
Looking for an XSLT editor and the AAFP templates to render CCR in a browser.
It’s important that digital signatures comply with regs such as HIPAA and FDA 21 CFR Part 11
Standard public key infrastructure (PKI) technology is typically used, but I understand it hasn’t done as well as hoped. I’ll attempt to explain in layman terms how it works for any readers who don’t know. (I realize many of you do know.)
Public-key cryptography, also known as asymmetric cryptography, is a relatively recent method where the decryption key is different from the encryption key. Putting them both together, they form a key pair: a public key for the “public”, and a private key which is used by those who enter the data. Typically the public key is the encryption key and the private key is the decryption key, but this is not always the case,
To sign a message, the signer’s information is encrypted with the private key. Anyone with the correct public key can decrypt the message. This does not protect the confidentiality because the digital signature is simply to verify the signer. The problem is it’s hard to know if the public key is being used by the intended recipient.
ELECTRONIC SIGNATURES IN GLOBAL AND NATIONAL COMMERCE ACT caused some conflict/confusion about the difference in electronic and digital signatures. Electronic signatures are images that are physically or logically attached to the signed data. These can be easily forged.
More on legalities/regulations:
UNIFORM ELECTRONIC TRANSACTIONS ACT (1999)
Digital Signature and Electronic Authentication Law (SEAL) of 1998
Government Paperwork Elimination Act (GPEA)
The Japanese are doing a lot of work on this right now:
A clinical management system for patient participatory health care support. Assuring the patients’ rights and confirming operation of clinical treatment and hospital administration.
The guideline of the personal health data structure to secure safety healthcare. The balance between use and protection to satisfy the patients’ needs.
Here is another interesting article: (I can only link abstracts for most, here.)
Definition, structure, content, use and impacts of electronic health records: a review of the research literature.
Interesting article re: Canada: Patient Accessible Electronic Health Records: Exploring Recommendations for Successful Implementation Strategies
Dave, this was a sobering post indeed, and the errors introduced by data transfer were very instructive. We are no where NEAR a safe, auto-populating EMR. You are correct that the claims codes are also important to exclude – and that timing is everything.
However, there are all kinds of ways to introduce errors into a medical record and I believe that when many patients enter data into their record they’ll introduce their own errors.
Over the years I’ve had patients tell me all kinds of things about their past medical history – that they have “the sugar,” that they “had their heart cleaned in 2001,” that they are “allergic to all antibiotics” (they know this because the pills “give them a headache”), etc.
The layers of complexity in this drive towards an error-free, patient-accessible, easily transferable EMR are mind boggling. I know that ePatients are very sophisticated and want to lead the charge – but I’d heartily recommend bringing the doctors and nurses with you. They will spot errors that you don’t catch – and you will spot errors that they don’t catch. We’re stronger together… Let’s unite for the good of all, ok?
Hi, Dr. Val…good to see your comment. I don’t think anyone wants to cut the medical professionals out of this. That’s where the “participatory” part comes in. It’s a partnership. And a good database/PHR would definitely delineate who gave what input.
For example, a patient telling you she had “the sugar” might clue you in on some issues you might not otherwise look at. It doesn’t mean it is what the patient thinks it might be. But it does give some detail you might not otherwise have.
I think, too, the issues are what comes across in transcription. I saw a prominent physician before I was diagnosed with Cushing’s. She put in her report to my PCP(which I only saw because I requested a copy) that I was depressed and needed to go in antidepressants. I never, ever said anything in our discussion to indicate I was depressed. Mad as heck that I wasn’t being tested, yes. Depressed, no. I did write a long letter to that same physician and asked that it be included in the record there, as did my PCP, who also called her and talked to her. There were other incongruities, too. However, my point is: She may have thought I was depressed. Maybe I did give that impression. I was just tired of being sick. I wanted to make sure her perception wasn’t the only one on file. It probably still is, although I was assured our letters would be added.
I think this emphasizes one very good use of a participatory system. At least it does to me.
Great to see you here, Dr. Val!
You raise a massively important point, which we’ve touched on before: being a patient doesn’t make me a doctor (duh).
Your response seems to suggest that I proposed leaving the docs behind. Nothing could be further from the truth – I often cite my own MD, Danny Sands, and before writing a word about this post I did just as you suggest: went over the topic with him.
This is such an important point. There is nothing about being an empowered patient that means “ditch the doctors.” I hope you’ll find time to read the e-patient white paper at the top of this blog, or at least Chapter 2, “Seven Preliminary Conclusions.” That’s the chapter that blew my mind on Jan. 27, 2008 and made me an e-patient. Conclusion #7 is The most effective way to improve healthcare is to make it more collaborative, and it says:
This is exactly what the new Society for Participatory Medicine, and its new Journal, are all about: taking this white paper out of “think tank” mode and building out the principles and practices to make it a reality.
Thanks again for visting. Presuming you’ll be at Health 2.0 / Ix next week in Boston, I’ll look forward to finally meeting you.
Robin,
Are you saying you want to see your file, to confirm that, and you can’t?
Hi, Dave. I had everything else that was on file there, plus a copy of each letter (my PCP cc’d me on hers). So, I don’t think I have ever asked for another copy. I didn’t mean to insinuate I couldn’t get one. I just never went back there. I should ask just to see, shouldn’t I?
Well, yeah, Robin dear, if you wanna be sure your record is correct, my advice above says yeah, go check it. :–)
BUT, you’re empowered – do what ya want! Express yoself! :–)