This is a complex post, so don’t jump to any conclusions.
Two weeks ago (gad, was it that long?) I asked you to think about something for a few days:
Imagine that for all your life, and your parents’ lives, your money had been managed by other people who had extensive training and licensing. Imagine that all your records were in their possession, and you could occasionally see parts of them, but you just figured the pros had it under control.
Imagine that you knew you weren’t a financial planner but you wanted to take as much responsibility as you could – to participate. Imagine that some money managers (not all, but many) attacked people who wanted to make their own decisions, saying “Who’s the financial planner here?”
Then imagine that one day you were allowed to see the records, and you found out there were a whole lot of errors, and the people carefully guarding your data were not as on top of things as everyone thought.
Two weeks before that post, I’d had a personal breakthough in my thinking. For a year I’d been a rabid enemy of Google Health, but now I said: I’m putting my data in Google and HealthVault: “I’m concluding that we can do more good by aggregating our data into large, anonymized databanks that smart software can analyze to look for patterns. Early detection means early intervention means fewer crises.” And I observed that the power of Web 2.0 “mash-ups” …
…lets people create software gadgets without knowing how they’ll be used, it lets people build tools that use data without knowing where the data will come from, and it lets people build big new systems just by assembling them out of “software Legos.”
So, I said, “I’m in.” I decided to punch the big red button and copy my personal health data into Google Health. What happened is the result of PatientSite’s “version 1” implementation, not their eventual full implementation, of the interface. To my knowledge, zero or one other hospitals have any interface at all, and as I’ll say later, I’m not even sure how much of the Google Health side of the connection is complete. Nonetheless, what I learned about my own data was quite informative, and quite surprising. (I’ve discussed what follows with hospital staff; this isn’t gossip behind anyone’s back. IMO, empowered people don’t gossip, they communicate clearly and directly with the people involved.)
When Google Health launched last May, my hospital’s CIO blog said “we have enhanced our hospital and ambulatory systems such that a patient, with their consent and control, can upload their BIDMC records to Google Health in a few keystrokes. There is no need to manually enter this health data into Google’s personal health record, unlike earlier PHRs from Dr. Koop, HealthCentral and Revolution Health.” So I went into my patient portal, PatientSite, and clicked the button to do it. I checked the boxes for all the options and clicked Upload. It was pretty quick.
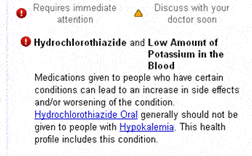
 But WTF? An alarm: “! Requires immediate attention” [see screen capture at right]
But WTF? An alarm: “! Requires immediate attention” [see screen capture at right]
Okay, yes, HCTz is my blood pressure medication. But low potassium? That was true when I was hospitalized two years ago, not now. What’s going on?
Then I saw the list of “conditions” it told Google I have. At left is a partial screen grab, and at right is the complete condition list that PatientSite transmitted: (Spoiler alert; this stuff is biological and might seem gross.)

Acidosis Anxiety Disorder Aortic Aneurysm Arthroplasty - Hip, Total Replacemt Bone Disease CANCER Cancer Metastasis to Bone Cardiac Impairment CHEST MASS Chronic Lung Disease Depressed Mood DEPRESSION Diarrhea Elevated Blood Pressure Hair Follicle Inflammation w Abscess in Sweat Gland Areas HEALTH MAINTENANCE HYDRADENITIS HYPERTENSION Inflammation of the Large Intestine Intestinal Parasitic Infection Kidney Problems Causing a Decreased Amount of Urine to be Passed Lightheaded Low Amount of Calcium in the Blood Low Amount of Potassium in the Blood Malignant Neoplastic Disease Migraine Headache MIGRAINES Nausea and Vomiting Nephrosis PSYCH Rash Spread of Cancer to Brain or Spinal Cord Swollen Lymph Nodes
Yes, ladies and germs, it transmitted everything I’ve ever had. With almost no dates attached. (It did have the correct date for my very first visit, and for Chest Mass, the x-ray that first found the undiagnosed lesion that turned out to be cancer. But the date for CANCER itself, the big one, was 5/25/07 – four months after the diagnosis. And no other line item had any date. For instance, the “anxiety” diagnosis was when I was puking my guts out during my cancer treatment. I got medicated for that, justified by the intelligent observation (diagnosis) that I was anxious. But you wouldn’t know that from looking at this.)
See how some of the listed conditions have links for More Info?  Let’s see, I was diagnosed with optical migraine. (I diagnosed myself, actually, by researching my symptoms and finding this illustrated site. That’s what e-patients do; it saves time in the doctor’s office… I brought a printout, with a dated list of episodes.) But optical migraine is not the impression you’d get from reading my Conditions list – in fact during my cancer workup one resident said “But you have headaches, right?” “No,” I said – “optical migraines, but without pain.” (Update 4/2: the illustration at left shows the dazzling pattern that an optical migraine produces.) So for that item in the conditions list, I clicked More Info. I didn’t get more info (i.e. accurate info) about my diagnosis, just Google’s encyclopedia-style article about migraines in general. (An optical migraine has little in common with migraines in general.)
Let’s see, I was diagnosed with optical migraine. (I diagnosed myself, actually, by researching my symptoms and finding this illustrated site. That’s what e-patients do; it saves time in the doctor’s office… I brought a printout, with a dated list of episodes.) But optical migraine is not the impression you’d get from reading my Conditions list – in fact during my cancer workup one resident said “But you have headaches, right?” “No,” I said – “optical migraines, but without pain.” (Update 4/2: the illustration at left shows the dazzling pattern that an optical migraine produces.) So for that item in the conditions list, I clicked More Info. I didn’t get more info (i.e. accurate info) about my diagnosis, just Google’s encyclopedia-style article about migraines in general. (An optical migraine has little in common with migraines in general.)
The really fun stuff, though, is that some of the conditions transmitted are things I’ve never had: aortic aneurysm and mets to the brain or spine. So what the heck??
I’ve been discussing this with the docs in the back room here, and they quickly figured out what was going on before I confirmed it: the system transmitted insurance billing codes to Google Health, not doctors’ diagnoses. And as those in the know are well aware, in our system today, insurance billing codes bear no resemblance to reality. (I don’t want to get into the whole thing right now, but basically if a doc needs to bill insurance for something and the list of billing codes doesn’t happen to include exactly what your condition is, they cram it into something else so the stupid system will accept it.) (And, btw, everyone in the business is apparently accustomed to the system being stupid, so it’s no surprise that nobody can tell whether things are making any sense: nobody counts on the data to be meaningful in the first place.)
It was around this time that I commented on Ted Eytan’s blog, “when you’re exporting to a new system, the rule is, Garbage Out, Garbage In. (Hint: visibility into the data in your old system may leave you aghast.)” We could (and will someday) have a nice big discussion about why the hell the most expensive healthcare system in the world (America’s) STILL doesn’t have an accurate data model, but that’s not my point. We’ll get to that.
And now we get to why I said, at the outset, don’t jump to conclusions. I’m mildly bitching about PatientSite, but that alone wouldn’t justify staying up to 3 in the morning all night writing a 2800 3500 word post; that one system isn’t a big deal for e-patients everywhere. (And besides, although PatientSite is old and clunky, a 1999 system if I ever saw one, it beats what most hospitals offer, and it did the job very well for me during my illness. And this is just version 1 of the interface; the current folly is not a permanent situation.)
The BIG question is, do you know what’s in your medical record? And THAT is a question worth answering. For every one of you.
See, every time I speak at a conference I point out that my 12/6/2003 x-ray identified me as a 53 year old woman. I admit I have the man-boob thing going on, but not THAT much. And here’s the next thing: it took me months to get that error corrected, because nobody’s in the habit of actually fixing errors. Think about THAT.
I mean, some EMR pontificators are saying “Online data in the hospital won’t do any good at the scene of a car crash.” Well, GOOD: you think I’d want the EMTs to think I have an aneurysm, anxiety, migraines and brain mets?? Yet if I hadn’t punched that button, I never would have known my data in the system was erroneous.
And this isn’t just academic: remember the Minnesota kidney cancer tragedy just a year ago, which arose at least partly out of an error that ended up in the hospital’s EMR system. Their patient portal allowed patients and family to view some radiology reports, but not the one that contained the fateful error.
The punch line came when I got over my surprise about what had been transmitted, and realized what had not: my history. Weight, BP, and lab data were all still in PatientSite, and not in Google Health. So I went back and looked at the boxes I’d checked for what data to send, and son of a gun, there were only three boxes: diagnoses, medications, and allergies. Nothing about lab data, nothing about vital signs.(So much for “no need to manually enter this health data into Google’s personal health record.”) And of the three things it did transmit:
- what they transmitted for diagnoses was actually billing codes
- the one item of medication data they sent was correct, but it was only my current BP med. (Which, btw, Google Health said had an urgent conflict with my two-years-ago potassium condition, which had been sent without a date). It sent no medication history, not even the fact that I’d had four weeks of high dosage Interleukin-2, which just MIGHT be useful to have in my personal health record, eh?
- the allergies data did NOT include the one thing I must not ever, ever violate: no steroids ever again (e.g. cortisone) (they suppress the immune system), because it’ll interfere with the immune treatment that saved my life and is still active within me. (I am well, but my type of cancer normally recurs.)
In other words, the data that arrived in Google Health was essentially unusable.
And now I’m seeing why, on every visit, they make me re-state all my current medications and allergies: maybe they know the data in their system might not be reliable.
Hey wait, a new article in the Archives of Internal Medicine (co-authored by our own Danny Sands, my very own primary) says Clinicians override most medication alerts. Could it be they’ve been through this exercise themselves, and they consider the data unreliable? (Or do they just not trust computers?) (Hey Pew Internet, wanna check for generational differences?) Who knows, perhaps the resident in the migraine story has learned early on that the data in his system is not to be taken at face value – I don’t know.
In any case, my hospital is very proactive and empowering to staff about root cause analysis for failures, with its “SPIRIT” program, and they’ll add any process or form that can catch potential errors. That’s good. But wait: On numerous visits, I’ve restated on those forms “no steroids.” But evidently what I write on the forms never gets entered into the system. Hm.
I work with data in my day job. (I do marketing analytics for a software company. We import and export data all the time.) I understand what it takes to make sure you’ve got clean data, and make sure the data models line up on both sides of a transfer. I know what it’s like to look at a transfer gone bad, and hunt down where the errors arose, so they don’t happen again. And I’m fairly good at sniffing out how something went wobbly.
And you know what I suspect? I suspect processes for data integrity in healthcare are largely absent, by ordinary business standards. I suspect there are few, if any, processes in place to prevent wrong data from entering the system, or tracking down the cause when things do go awry.
And here’s the real kicker: my hospital is one of the more advanced in the US in the use of electronic medical records. So I suspect that most healthcare institutions don’t even know what it means to have processes in place to ensure that data doesn’t get screwed up in the system, or if it does, to trace how it happened. Consider the article in Fast Company last fall, about an innovative program at Geisinger. Anecdotally, it ended with this chiller:
“… a list of everybody that accessed the medical record from the time he was seen in the clinic to two weeks post-op.’There were 113 people listed — and every one had an appropriate reason to be in that chart. It shocked all of us. We all knew this was a team sport, but to recognize it was that big a team, every one of whom is empowered to screw it up — that makes me toss and turn in my sleep.”
In my day job, our sales and marketing system (Salesforce.com) has very granular authorizations for who can change what, and we can switch on a feature (at no extra cost) to track every change that’s made on any data field. Why? Because in some business situations it’s important to know where errors arose – an error might cause business damage, or an employee might sue over a missed quota.
So I’m thinking, why on earth don’t medical records systems have these protections? If a popular-priced sales management system has audit traces, to prevent an occasional lawsuit over a sales rep’s missed commission, why isn’t this a standard feature in high-priced medical records systems? In any case, in the several weeks since these discoveries started, as far as I know they haven’t figured out how my wrong data got in there. And without knowing how the wrong data got in, there’s not a prayer of identifying what process failed.
BUT AS I SAID, this is not about my hospital; a problem at my hospital affects only one scrillionth of patients in the US, not to mention the rest of the world. And please don’t blame my hospital’s CIO; I think what he wrote about the Google Health interface was overzealous, but I believe he’s a good man, committed to helping us own our own data (his work on the Google Health advisory board was unpaid), and this post isn’t about him: as far as I know, this hospital is farther along than anyone else: hardly anyone else has implemented a Google Health interface. (Perhaps for good reason.) Nor is this a slam on Google Health.I haven’t probed yet into whether there are limitations in what it does; might be fine, might not. Heck, neither PatientSite nor I have put any good data into it yet. (And I haven’t even touched HealthVault.) None of that is my point. Rather, my point is about the data that was already in my PHR, uninspected. For that, let’s return to my previous post:
Then imagine that one day you were allowed to see the records, and you found out there were a whole lot of errors, and the people carefully guarding your data were not as on top of things as everyone thought.
In my day job, when we discover that a data set has not been well managed, we have to make a decision: do we go back and clean up the data (which takes time and money), or do we decide to just start “living clean” from now on? My point, my advice to e-patients, is:
- Find out what’s in your medical record. What’s in your wallet, medically speaking? Better find out, and correct what’s wrong.
- Get started, manually, moving your data into Google Health, HealthVault, or some such system. I’ve heard there are similar PHR systems (personal health records), not free but modestly priced, that can reportedly make this easier. I’m sure their friends will show up here in the comments. (Feel free to post product info links in the comments, everyone.)
- Let’s start working, now, on a reliable interoperable data model. I know the policy wonks are going to scream “Not possible!” and I know there are lots of good reasons why it’s impossibly complex. But y’know what else? I’ve talked to enough e-patients to be confident that we patients want working, interoperable data. And if you-all in the vendor community can’t work it out, we will start growing one. It won’t be as sophisticated as yours, but as with all disruptive technologies, it will be what we want.And we’ll add features to ours, faster than you can hold meetings to discuss us.I have to say, while researching this post I was quite surprised at how very, very far the industry has to go before reaching a viable universal data model. New standards are in development, but I’m certain that it will take years and years and gazillions of dollars before any of that is a reality. (What, like costs aren’t high enough already?) In the meantime, your data is probably not going to flow very easily from system to system. Far, far harder than (for instance) downloading your data to Quicken from different credit card companies and banks. (Wizards and geeks refer to this “flow” issue as “data liquidity.” We’ll talk about that in the future.)
- Let’s start working, now, on an open source EMR/PHR system. The open source community creates functionality faster, and more bug-free, than commercial vendors do – and nobody can latch onto proprietary data in such systems to milk more margin out of us… because it ain’t proprietary.The great limitation of open source is that it’s generally not well funded. But you know what? Every person in America (including software engineers) is motivated to have good reliable healthcare systems, and I assert that the industry ain’t getting’ it done on their own. As I said in my Thousand Points of Pain post (cross-posted on IBM’s Smarter Planet blog as A business thinker asks, what will it take to get traction?), it’s fine with me if industry vendors come along too – but I would not stake my life on their moving fast enough for my needs. Or your mother’s needs.
Want a case study with real consequences? Recall what happened last year to famed Linux guru Doc Searls when he couldn’t read his own scan data, because good cross-platform image viewing tools weren’t available. (His prescription: the patient should be the platform and “the point of integration.”) Well, okay, so Doc was a year ahead of me. I’m catching on. This illustrates why I think people from outside the profession may be our greatest asset in building what patients really need: patients tend to build what they want. And we who work with data all day know that these problems are not unsolvable.
My bottom line: I think we ought to get our data into secure online systems, and we shouldn’t expect it to happen with the push of a button. It’ll take work. So let’s get to work. You know the work will be good for you, and heaven only knows what you’ll learn in the process. You’ll certainly end up more aware of your health data than when you started. And that’s a good thing.
Minor edits made 4/12/2009, and 1/5/2012 and 9/19/2022 for clarity and to adjust to this blog’s new format




When I say that your post does not surprise me, I am saying that I have known this stuff for several years now. The essential problem is that medical knowledge is being handled by information/data geeks who don’t actually understand what they are supposed to be doing.
The issue is a deconstruction/reconstruction phenomenon that goes for all electronically stored data. My knowledge about a patient is a single ‘thing’ which includes a substantial amount of causal reasoning.
Just look at these four items:
CANCER
Cancer Metastasis to Bone
CHEST MASS
Chronic Lung Disease
Now I accept that these are not accurate (some one probably wrote “there is a distinct lack of evidence of bone metastasis from lung cancer” and that got you the code!), but from an oncologist’s view point (that’s me!) the data actually looks like this:
Chronic Lung Disease
[complicated by new] CHEST MASS
[diagnosis] CANCER
[stage] Cancer Metastasis to Bone
And from the MDs perspective calls up a whole lot of missing data which will make this data useful for analysis. Things such as:
can you quantify smoking behaviour? how was the mass found? what symptoms? how was the diagnosis made? what was the delay in diagnosis? what type of cancer was it? what staging tests were done, how was it found in the bone (pain or images)? what treatment was administered? what side effects resulted from each treatment? etc, etc.
The problem is that what you have transferred is just an inventory, and an undated one at that. But believe me, I can show you real cases where the dates can be fooled as well. Just consider TWO cancers found on the same day and immediately you can’t tell which one is the reason for chemotherapy, radiotherapy, immunotherapy, hormone therapy, palliative care, etc.
The present electronic systems deconstruct our knowledge into an inventory of medical parts – I like to use a car analogy here, when you order a new Merc, you don’t expect to get home and find the PARTS of a Merc piled in your driveway, you expect THE CAR, that is it has to be put together. So the issue for me with IS in health is not whether you can store my data (notice I didn’t say knowledge!), but whether you can reconstruct my knowledge. This means write a database report which will give me something back which I can read and say “yes, that’s what happened” IN ALL CASES.
Now you may say this can’t be done, well you would be wrong. It’s just that the temporal sequence is not the right methodology for expressing the knowledge, for that you need a medically-trained brain. So your statement would look something like this:
“On 1/2/2007, a patient with [chronic obstructive lung disease (8 year history)] presented with [hemoptysis (2 day history)]. There was a [normal physical examination]. A chest x-ray showed a [3cm lung mass]. Biopsy of this mass revealed [adenocarcinoma]. ** On 1/3/2007 a diagnosis of [adenocarcinoma] of the [right] upper lobe of the lung ([C34.1])was established. On 10/3/2007, a stage of [iT2iN0iM0] was established with CT and PET scan. On 12/3/2007 a decision was made to provide [curative] treatment using [primary] radiotherapy ([60 Gy/ 30 Fx]), [concurrent] chemotherapy ([cisplatin/paclitaxel]) and [adjuvant] immunotherapy ([Arressa]).**”
But you should note with the reading that these is a ‘logical’ flow to this. The whole thing is my knowledge, but the information that makes up the knowledge (e.g. diagnosis, stage) has a nomenclature so that it can be stored as data. But more than that the text between ** and ** is actually very static in form although there is marked variation in the actual entries. This statement was one that I could write from my IS for EVERY PATIENT, so I knew that my knowledge was faithfully represented in the system. Sadly that was just one system and no other has matched its performance.
There is the feeling around the informatics traps that if all that medical data could just be put into one place, then NLP and mathematical analysis will tell us what we need to know about medicine. And I think you have shown very clearly, that the only answer you get from the analysis of rubbish is some distilled form of …. rubbish. So why bother.
I have reached several conclusions:
+ unfortunately data recorded without involvement of the MD is NOT medical data.
+ MDs of different types are so dissimilar that one system cannot fit them all – e.g., GPs reach a diagnosis in only 30% of their cases, while I generally won’t see a patient without a cancer diagnosis.
+ IS purchased by managers serve only managers, and MDs.
+ top down approaches will result in the data stupidity you have described.
+ MDs have to fundamentally change their attitudes if they want to change this outcome (unfortunately I don’t think they will, or do)
I am one of those information/data geeks who doesn’t know what they are doing and fouled up the whole system which would have just fine until we got a hold of it.
I know of only one MD who routinely dictated and transcribed observations.
I don’t know of any who routinely revisit their “files” to see if they make sense.
Patients are not doctors but they are the only one likely to have a continuing interest in seeing that their history makes sense.
Or should we bring back the scribes and Pharisees?
Hi, Andrew and Jim….
I suppose this is the statement to which Jim is responding:
Well, that could be true at some point and time. However, it is the responsibility of the client to make sure the data modeler understands what s/he wants. Of course, that would mean the client would know. And we all are cognizant of the fallacy of that remark. In addition, what the client wanted was not necessarily (or probably) what the patient needed/wanted, as is stated many ways in prior comments. So, it’s really a moot point.
Jim, I apologize that the statement came out too harshly, and I agree with you that data quality and assurance amongst MDs is really badly done. But that is a different but related issue.
I did clean and QA my data repeatedly (set up a system where patient data was reviewed at least 4 times from initial consultation to final discharge) in an IS that did represent my knowledge properly. They did get it right, and we MDs did QA the data … and it was BEAUTIFUL!
But with time, that working system has been slowly crucified by the introduction of “features” which now have compromised the representation.
Now I work with a different system that does not and CANNOT represent my knowledge (there are bits missing, and its an inventory. And here is my problem – the data modellers come in for 1-2 days and ask some superficial questions and leave. I ask them to keep in touch, to show me what they are doing in prototype, but I met with silence.
For me to take the responsibility for making sure the data modeller understands what I want, I would need to take hammer and nails to work and nail their feet to the floor. The data modellers doesn’t want to be there and are not taught how to understand the data structures.
I work with an academic group of logicians and informaticians, and the lead academic has taken almost 12 months of persistent explanation to begin to see what is different in the medical knowledge issues. It took me 6 months to convince the DB lecturer of the reasons why the DB had to be a particular way based on the nature of medical knowledge. No data modeller hangs around that long, and most aren’t that bright either.
The problem is that we need KNOWLEDGE modellers, not data modellers.
So how did one IS get it right? Well, they had a MD who kept telling them, that’s not how we think until it was done right.
My final point is this: the modeller has to spend a lot of time getting to understand the medical knowledge, and the MD has to spend a lot of time learning to read the modeller notation ….. and then work together to get it right.
PS Robin, are you saying its the modeller’s fault for taking money for the unachievable, or the MD’s fault for not specifying the unintelligible?
Andrew, this is a great discussion. I don’t think “fault” is a good word. Good data modeling (or knowledge modeling…like that term!) takes a lot of time, not one or two days. Time is money for both parties involved. And if every physician/work group has to reinvent the wheel each time….
Yes….that’s how it’s supposed to work. Is there a way to do this so it works in such a way (we call it “generic modeling”) most healthcare professionals and their patients can use it effectively? I believe so. But even that is a compromise because it won’t meet some needs of some providers.
So, what if SOMEONE (Uncle Sam, me, you, anyone) decided to build this generic database? (And there are already bunches out there, although few, if any, include the patient participation model.) What we need to achieve is doing what you did, but with the patient involved.
Is there a way to do this to minimize frustration for all parties? Do we do this using what is already there and building on it or do we start from scratch? Maybe we can figure all that out.
This quote above is probably a little harsh.
“And so they have carried that erroneous data for years and years and EVERYBODY knowingly winks because it is well known that’s the only way to get paid/reimbursed. How sick is a system that forces its professionals to consciously write erroneous data and then hides this simple fact under total silence. You’ve just surfaced a “secret de polichinelle” (an Open Secret) for the healthcare professionals.”
Although it is true that the perception from this article is that part of the problem is that Doctors enter information to ensure they get paid – I think that focusing on this point to resolve the health information problems would be a mistake.
How can I make this statement, well I have worked in other countries (so called single payer countries or Socialized Medicine) like Canada, New Zealand, Australia and England in which reimbursement is not as bigger concern (but is still a concern). And guess what, the patient medical records there as just as bigger mess. England has just spend billions of dollars on a nation wide computerized medical record program, and it is a mess.
Secondly, we need to be aware that the PHR is supposed to contain the patients Medical Record. The hospital in question choose to send through the billing and claims information – which is not the information that should be used to make medical decision. Think about it, do the police try to solve a house robbery using the victims insurance claim? – of course not, it does not make any sense at all. The police use the crime scene report to solve the crime and the insurance company using the claim information to decide how much to pay. So why would it make sense in health care for a patient (or doctor) to look at the claim information? The only thing it will tell you is that a claim was made on this date.
Don’t get me wrong, this problem still needs to be solved. And I am sure that patient access to their records will go a long way to helping (think of it as oversight – we, the patients, have the largest vested interest in making sure our records are correct).
Great post – hopefully it will help open peoples eyes.
I have to dis-agreed with this comment:
“And so they have carried that erroneous data for years and years and EVERYBODY knowingly winks because it is well known that’s the only way to get paid/reimbursed. How sick is a system that forces its professionals to consciously write erroneous data and then hides this simple fact under total silence. You’ve just surfaced a “secret de polichinelle” (an Open Secret) for the healthcare professionals.”
Although it is true that the perception from this article is that part of the problem is that Doctors enter information to ensure they get paid – I think that focusing on this point to resolve the health information problems would be a mistake.
How can I make this statement, well I have worked in other countries (so called single payer countries or Socialized Medicine) like Canada, New Zealand, Australia and England in which reimbursement is not as bigger concern (but is still a concern). And guess what, the patient medical records there as just as bigger mess. England has just spend billions of dollars on a nation wide computerized medical record program, and it is a mess.
Secondly, we need to be aware that the PHR is supposed to contain the patients Medical Record. The hospital in question choose to send through the billing and claims information – which is not the information that should be used to make medical decision. Think about it, do the police try to solve a house robbery using the victims insurance claim? – of course not, it does not make any sense at all. The police use the crime scene report to solve the crime and the insurance company using the claim information to decide how much to pay. So why would it make sense in health care for a patient (or doctor) to look at the claim information? The only thing it will tell you is that a claim was made on this date.
Don’t get me wrong, this problem still needs to be solved. And I am sure that patient access to their records will go a long way to helping (think of it as oversight – we, the patients, have the largest vested interest in making sure our records are correct).
Great post – hopefully it will help open peoples eyes.
I thought I had responded to these continuing and important blogs of ePatient Dave, the Boston Globe, Dr. Halamka at Beth Israel Deaconess, and PHRs (Google Health). But I can’t find my entry. Forgive me if I re-submit.
One must go back to ePatient Dave’s main point (albeit difficult to find given all the exchanges and text) — “Do you know what’s in your medical record? THAT is the question worth answering.”
It doesn’t matter if the data are stored on paper, on analog photographic film, or on a digital storage medium. The only way one will be truly responsible for one’s health is to get copies (analog or digital) of one’s complete, episodic medical record, review the record with one’s provider(s) if necessary, and if errors are are found, correct them. Because one deals with people, processes, and technologies, data inaccuracies occur all the time!
Thankfully, since the 1970s, patients have been allowed to access the information contained in their medical records, and since HIPAA “I” (1996), patients have been allowed to add addenda to their records. However, similar to obtaining and correcting the data contained in one’s credit report, one must ask to do this.
As a health information management professional for over thirty years and long-time member of the American Health Information Management Association (AHIMA) whose banner remains “Quality Information for Quality Healthcare”, I never NOT obtain copies of my episodic medical record for review, archive, and information exchange purposes. Hopefully your readership will do same.
For example, as a health information management professional (fortunately or unfortunately) I knew only too well that when I was hospitalized five years ago my clinical records (created and stored in both analog and digital formats) would contain inaccuracies. One operative report contained my correct demographic information in the report header but described me as male (I’m a female) with inoperable colon cancer in the report body! (Either the surgeon or the transcriptionist mistakenly switched the dictation based on another case that day.) Subsequently, these data were coded as such for billing /reimbursement purposes (ICD / CPT) and for clinical purposes (SNOMED) – making no difference had the data populated a Google or Microsoft or other PHR.
In summary, to answer another question asked in one of the blogs, “Who’s going to validate and correct the data?”, the good news is that health information management professionals working in all types of healthcare provider organizations are not only trained but tasked to validate these data. The not-so-good news is that given staffing constraints and other similar issues, it is not and never will be possible to audit 100% of the medical record content in 100% of the cases. Therefore, only YOU, the patient, can and must review and correct the data.
I didn’t know about E-Patient Dave until I read the recent article in the Boston Globe. However, I have been following his example for a number of years. I have tried, with reasonable success, to find physicians who are comfortable with my willingness to search out information by weekly reading of WebMd in several specialties. Since my PCP is an MIT graduate, she has learned to deal with the strange behavior of male engineers. This reading, for example, has enabled me to find some side effects of various medications that were unknown to the prescribing physician.
I am a Medicare patient and use both Blue Cross Bronze and Caremark for mail prescriptions.
The download to Google Health, while not free of difficulty, worked and my records are updated by both organizations routinely. As Dave noted, I only get the date of down load for past records but new updates are probably correct to within a few days. I do obtain and hold all of the input data and diagnosis for things like CAT scans and EKG’s
Since I know a number of practicing physicians, I am familiar with the insurance code process and could figure in most cases why a condition code for something I didn’t have was used.
I can access my test results via MGH Patient Gateway, which I use. Unfortunately, I would have to manually transcribe these results given the rather crude interface for that system. I would have to request physician’s notes in printed form if I wanted to access as well.
For example, I have to use my PCP’s personal email address for sending something like a picture.
Actually, it saddens me that the coding skill of a physician rather than their diagnostic skill seems to have the most impact on his/her income. I have another source of data in that a Medicare contractor, at a rather significant expense I believe, sends me the text equivalent of an insurance code, the fictitious price the physician would charge, what Medicare actually pays, what BCBS pays and what I might pay if something mysterious happens.
I recognize that some of the difficulties listed above are due to HIPPA compliance requirements.
I recently recognized that I am a heart to one physician, eyes to another, skin to a third, teeth to a fourth and a thyroid to a fifth. I suspect that I am over-medicated as a result and my next endeavor is to see if all those pills are really necessary
Finally, I have used a former Ukrainian Olympic coach as my personal trainer for the last 10 years. (That’s a post in itself) This has probably done more to keep me in good health than anything else.
Great to hear from you, Wendell. Sounds like you’re indeed an e-patient, engaged in your care, and doing as much as you can online!
Have you always been doing this, or did it get started during some crisis a while back?
btw, it sounds like *I’m* following *your* example, not the other way around – I started using PatientSite in 2003 but like many people I didn’t get off the dime and get engaged in my care until trouble arose.
It wasn’t a crisis in the sense that you describe but about 10 years ago I got a diagnosis of normal pressure glaucoma, which when I pressed, translated to “I don’t really know what’s wrong with you, I don’t know what to do about it and why don’t you see a glaucoma specialist before you go to the Perkins Institute.”
The recommended glaucoma specialist had a 6 month backlog so I turned to the internet and with a bit of luck, quickly found the one US specialist who actually had positive results with my particular version of glaucoma. The rest is a rather long story where I finally realized that I was the only person who really had the time to think about the system aspects of both disease and medication side effects. One key for me was the selection of physicians, primarily female, who were not threatened by my approach to heath care delivery. BCBS Bronze makes this process easy for me.
Well hell, Wendell, that sounds like I’d consider it a crisis! Not in the sense of “the house is on fire,” but to me “The system has nothing to offer you” is as good a case for action as anything.
In fact maybe we should add that to the list of ways that “the system” might not provide what we need. We know about cases where medical science has no answer at all, and cases where the answer exists but a particular doc doesn’t know about it; but then there are cases where the answer exists but you can’t get at it, because of backlogs.
I like this line of thinking. There are many challenges in healthcare, and for everyone, the slogan at the top of our blog can be supplemented with “patients can help.”
Amen!
Just had an incident where my SS# was attached to a different patient’s name in the electronic med record. And the health facility will not tell me where the error occured, or how long someone else’s name was linked to my ss# and my medical record. Discovered accidentally when the lad attendant called me by the wrong name…. The hospital ethics person states only that they have taken care of it and counseled the individual involved! Then try reviewing your own EMR. They act like you are neurotic even though the reason is that your record had been mixed up with another person…duh!
Lots of errors/lots of privacy issues/